SEAL: Towards Safe Autonomous Driving via Skill-Enabled Adversary Learning for Closed-Loop Scenario Generation
Benjamin Stoler, Ingrid Navarro, Jonathan Francis and Jean Oh
Abstract
Verification and validation of autonomous driving (AD) systems and components is of increasing importance, as such technology increases in real-world prevalence. Safety-critical scenario generation is a key approach to robustify AD policies through closed-loop training. However, existing approaches for scenario generation rely on simplistic objectives, resulting in overly-aggressive or non-reactive adversarial behaviors. To generate diverse adversarial yet realistic scenarios, we propose Skill-Enabled Adversary Learning (SEAL), a scenario perturbation approach which leverages learned scoring functions and adversarial, human-like skills. SEAL-perturbed scenarios are more realistic than SOTA baselines, leading to improved ego task success across real-world, in-distribution, and out-of-distribution scenarios, of more than 20%.
Motivation
Scenario Realism
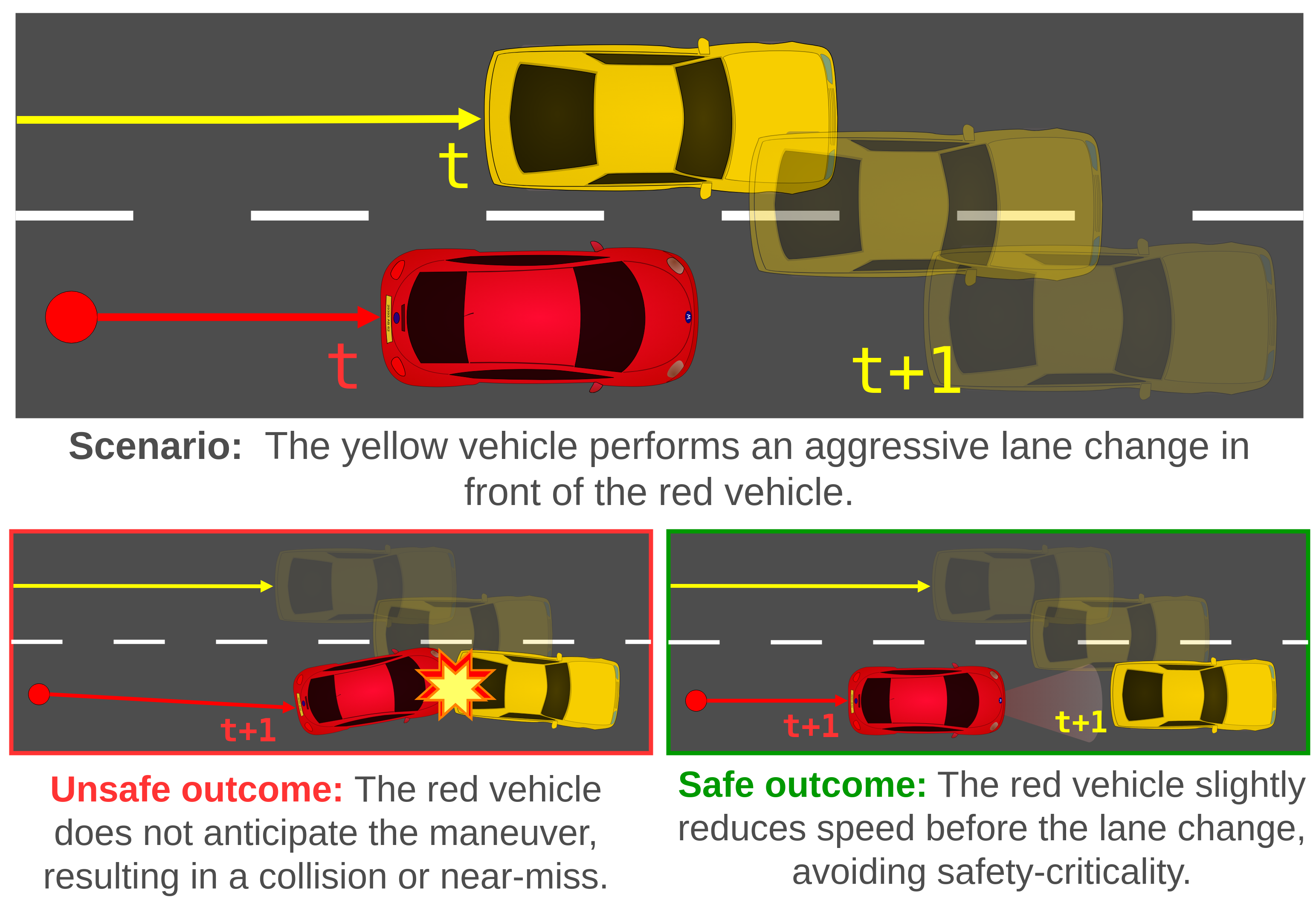
State-of-the-art (SOTA) adversarial scenario-generation approaches often struggle to provide useful training stimuli to closed-loop agents. Specifically, we identify that recent SOTA approaches generally limited view of safety-criticality, often focused on optimizing unrealistic and overly-aggressive adversarial behavior, while also lacking reactivity to an ego-agent’s behavior diversity.
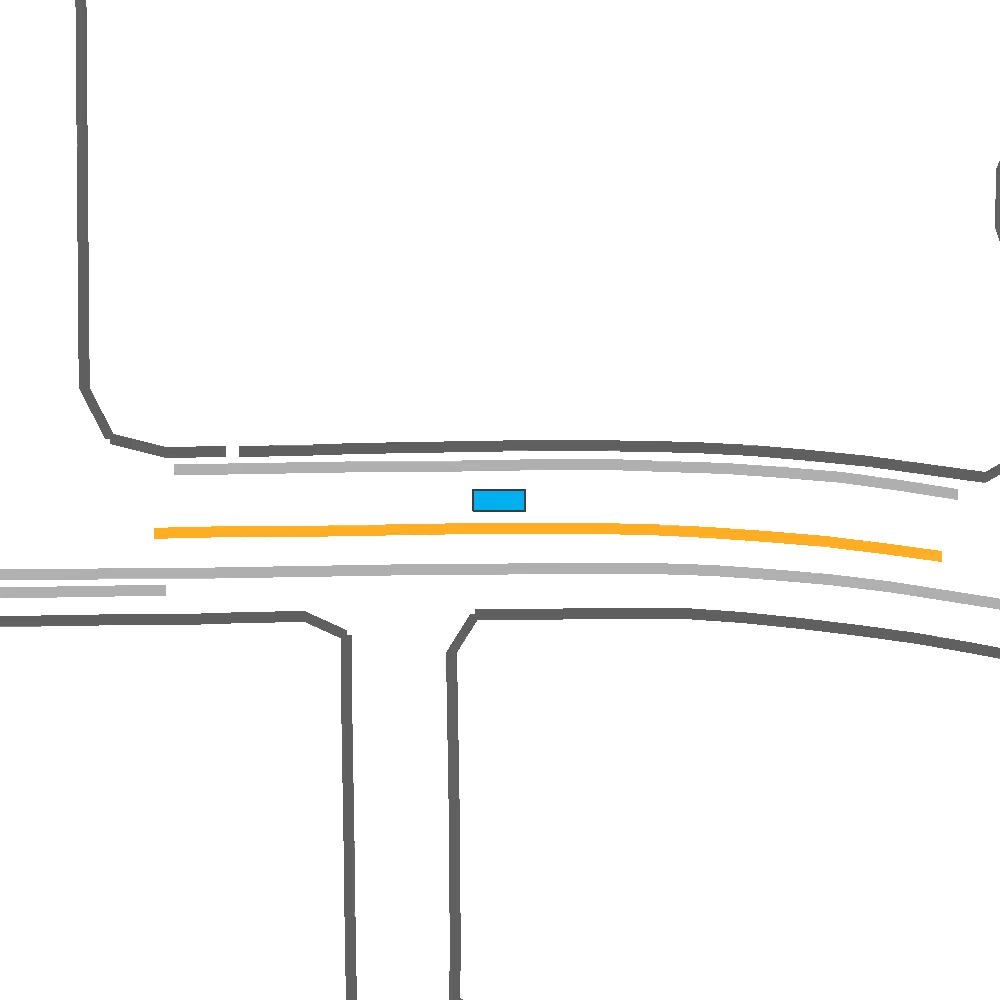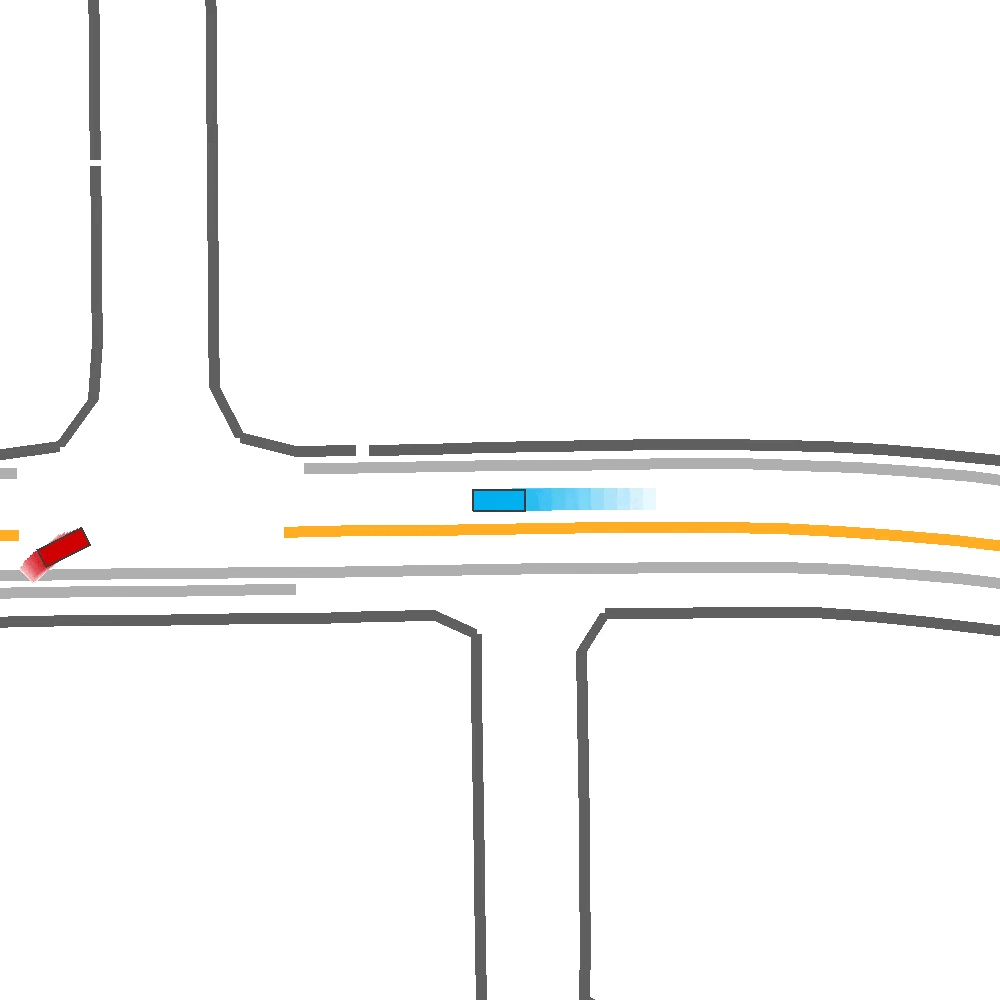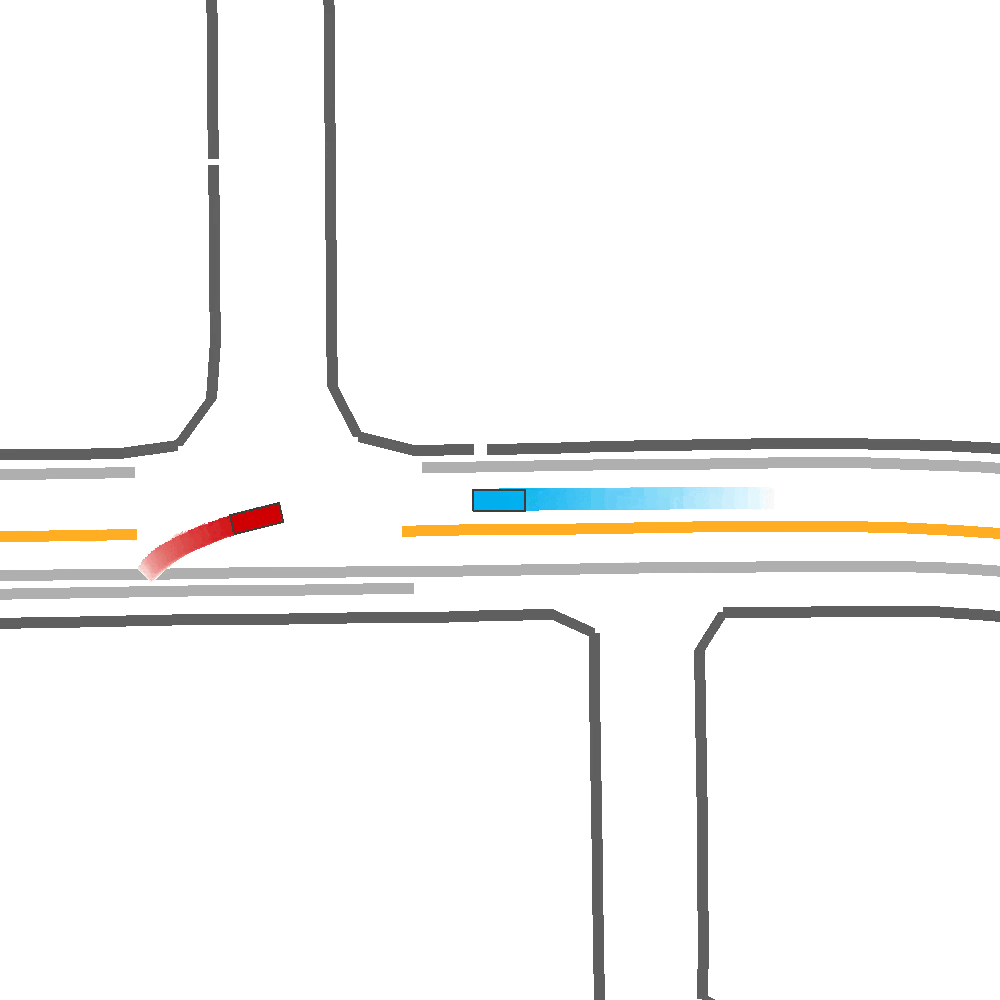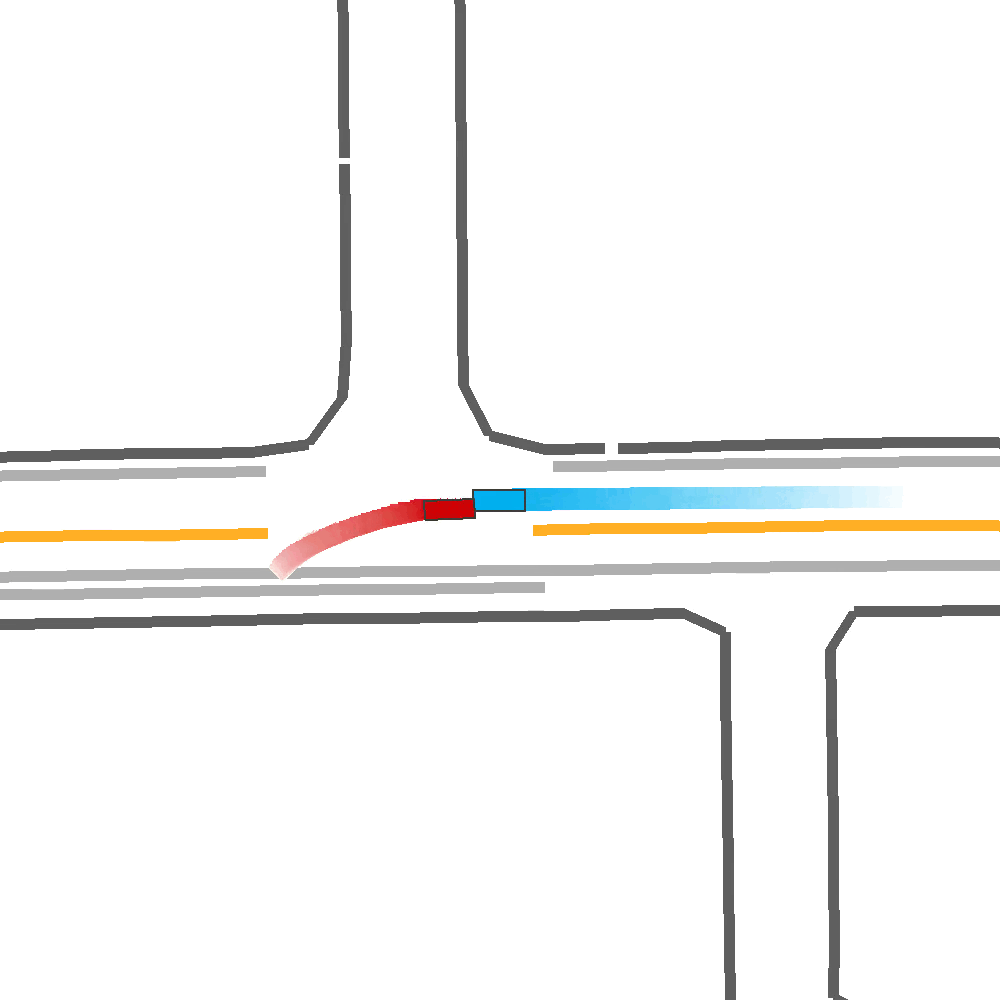
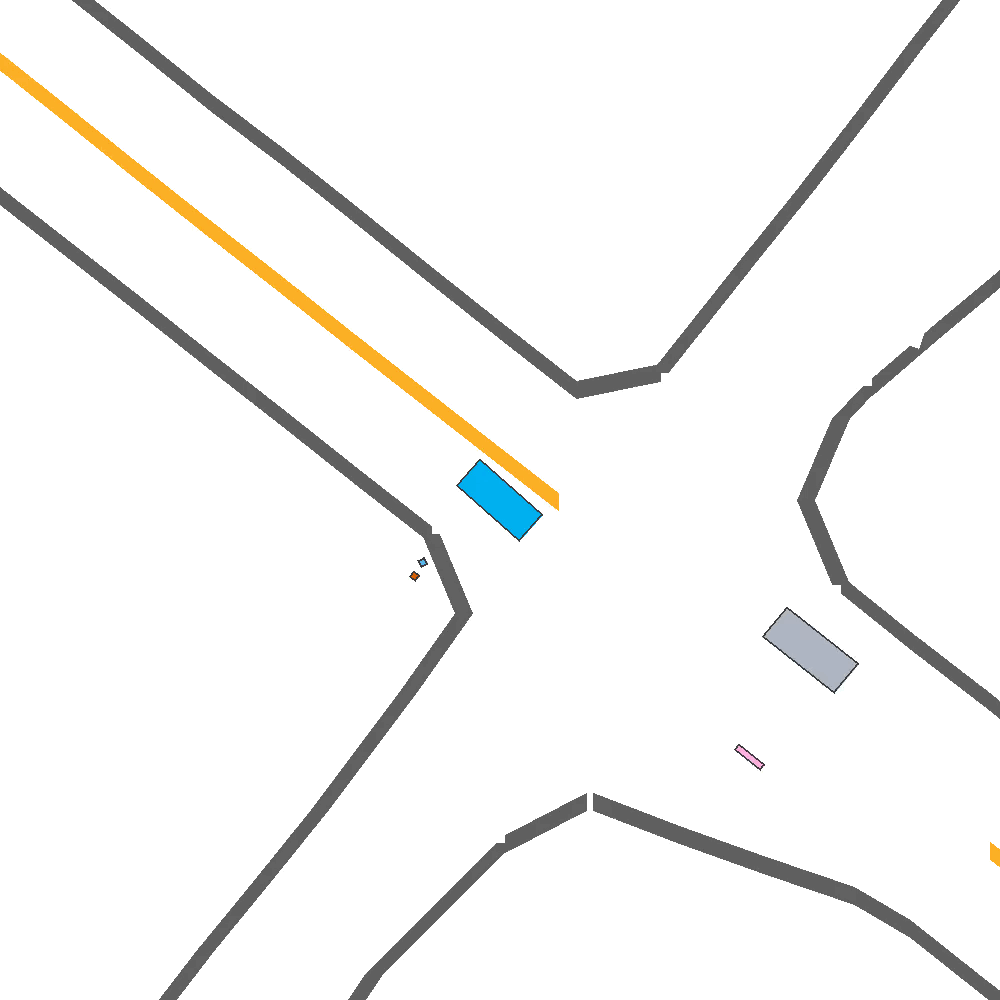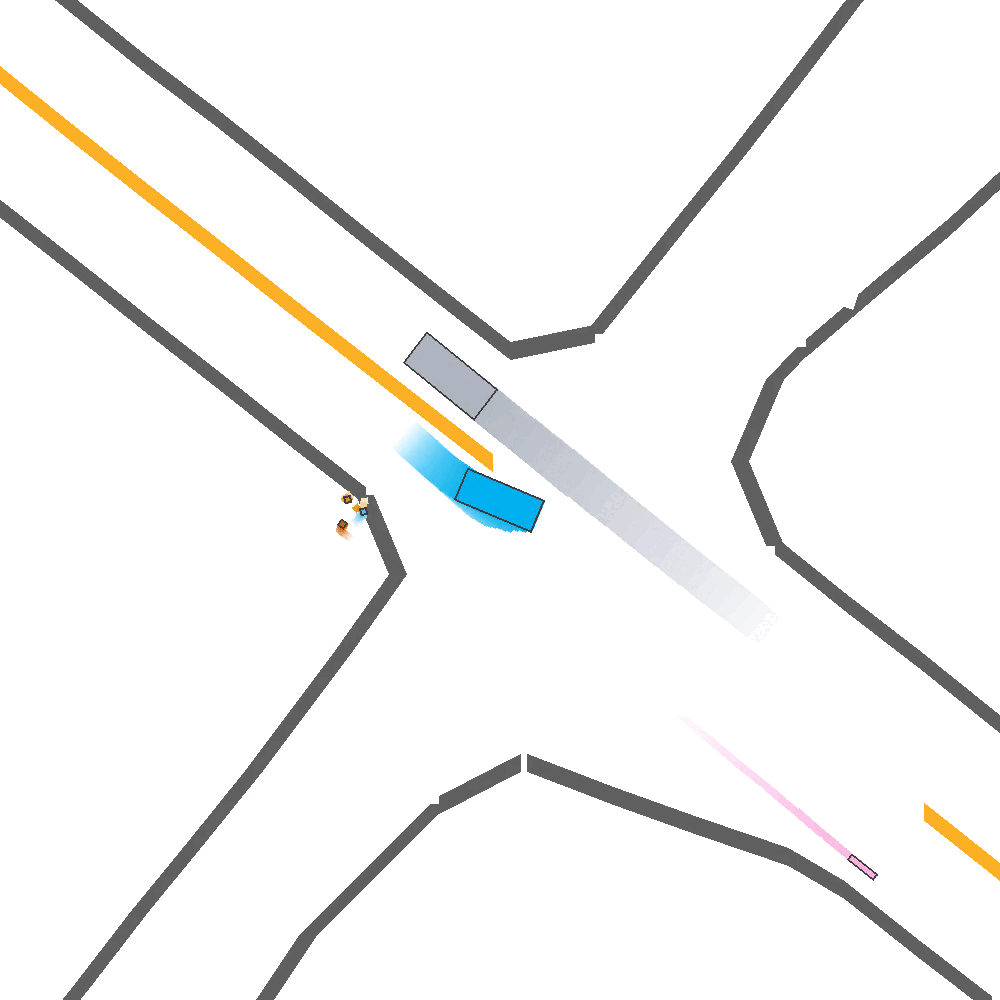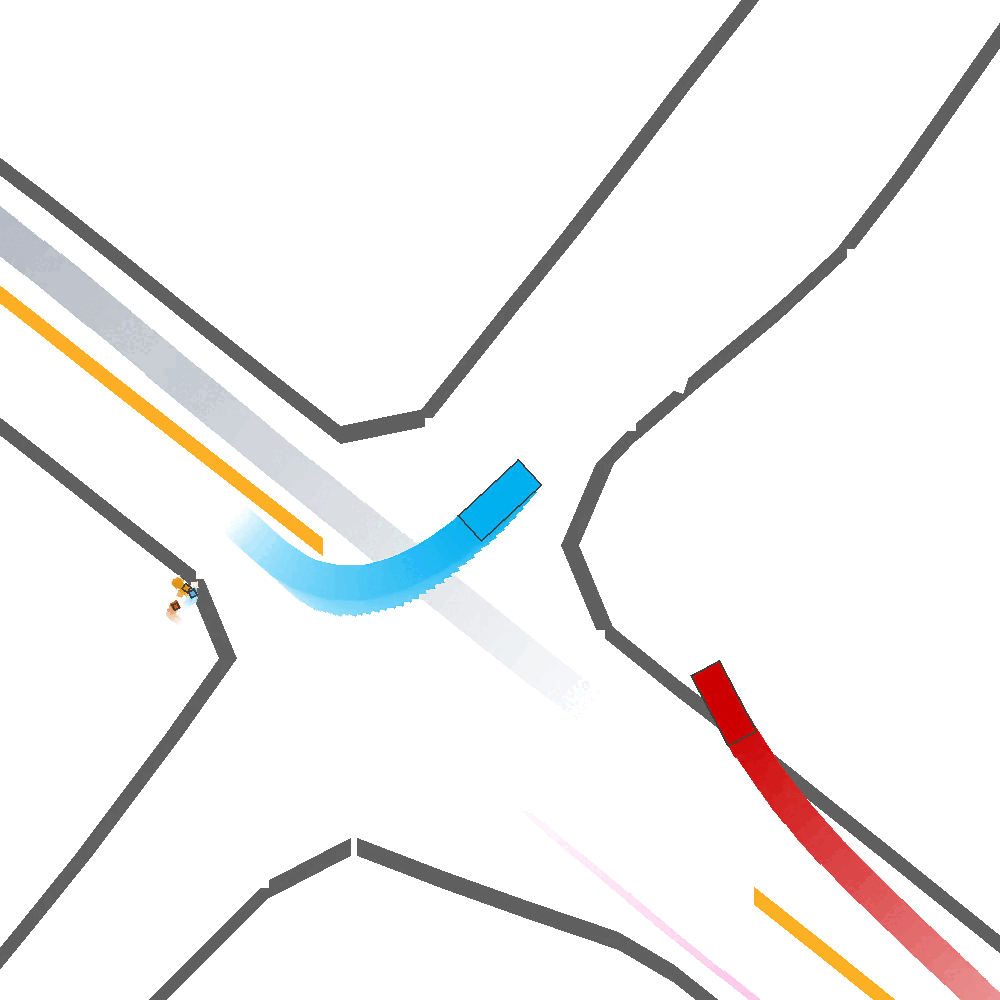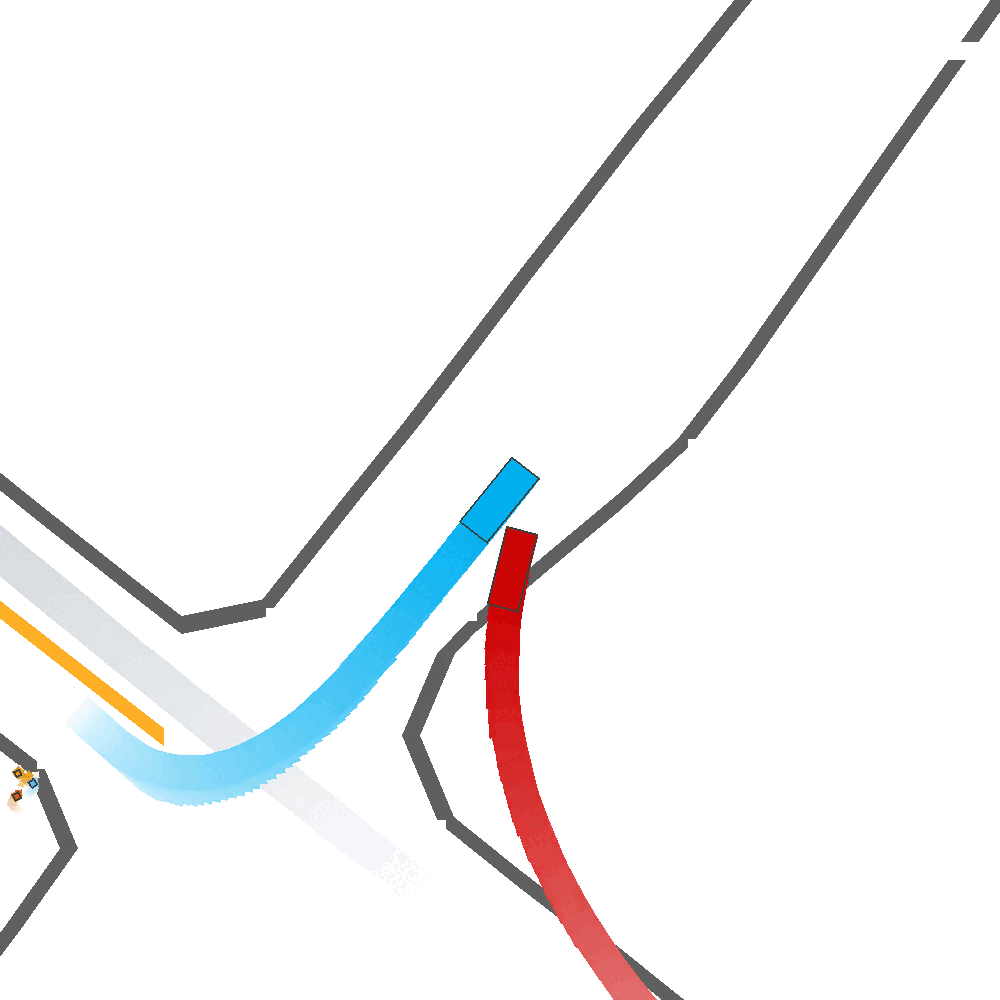
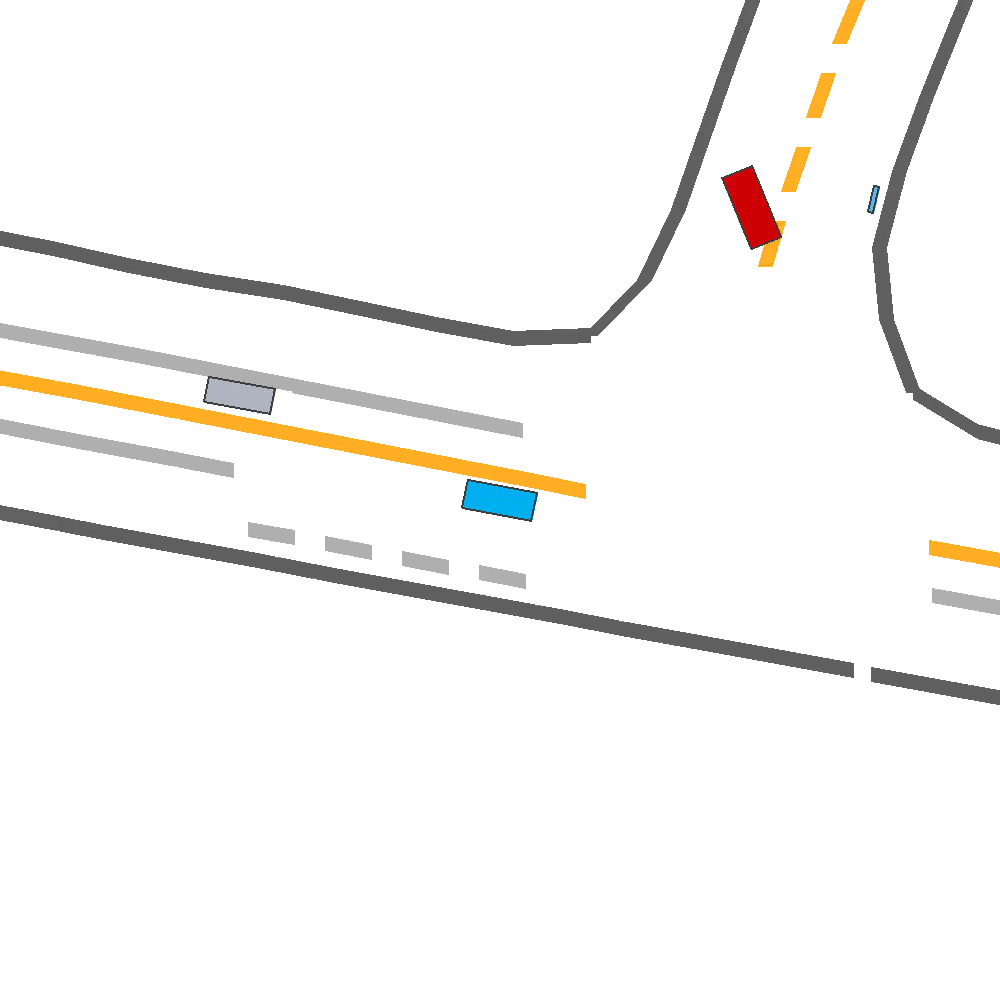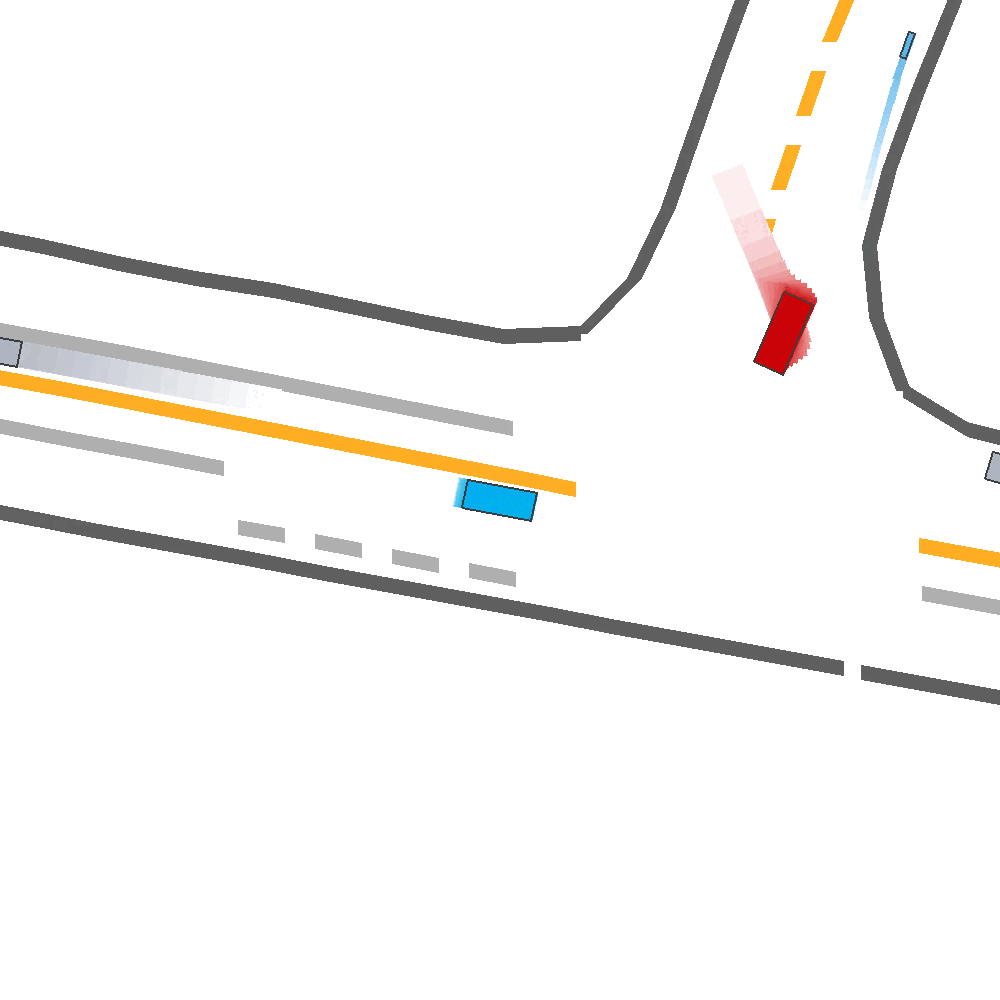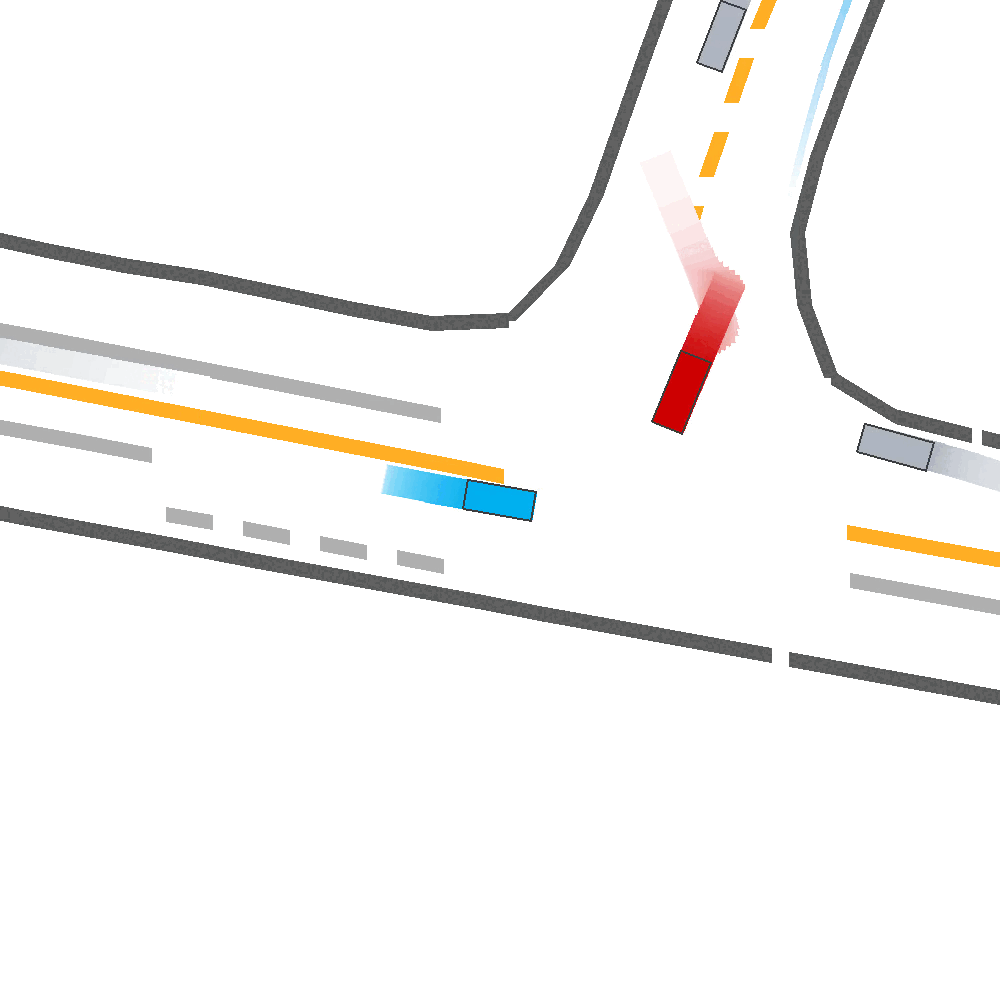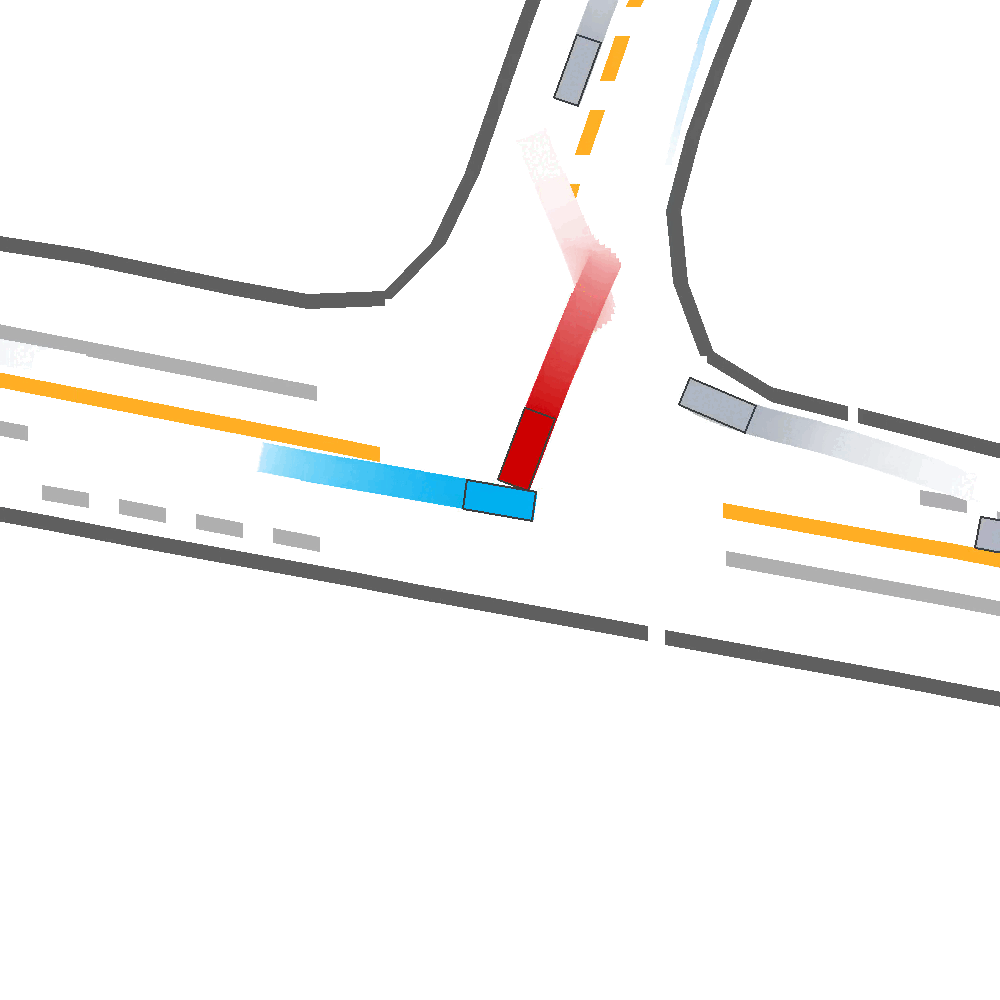
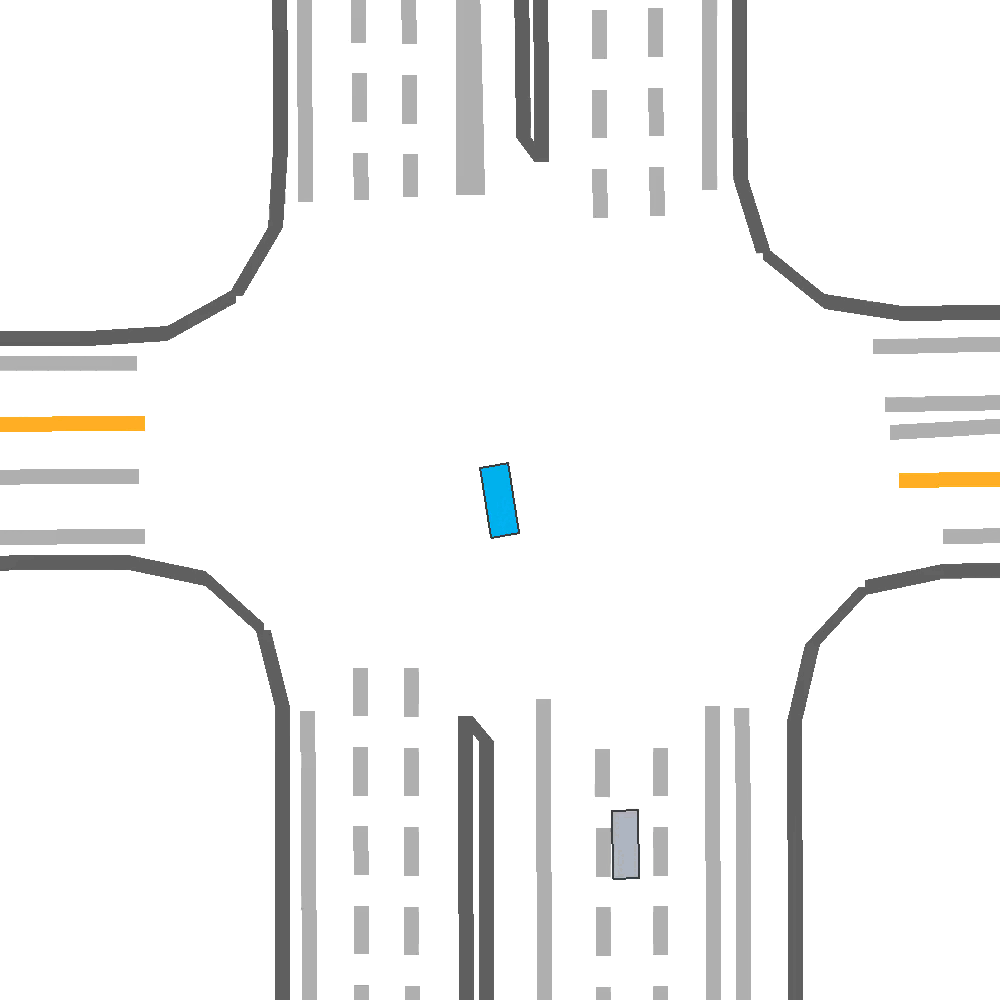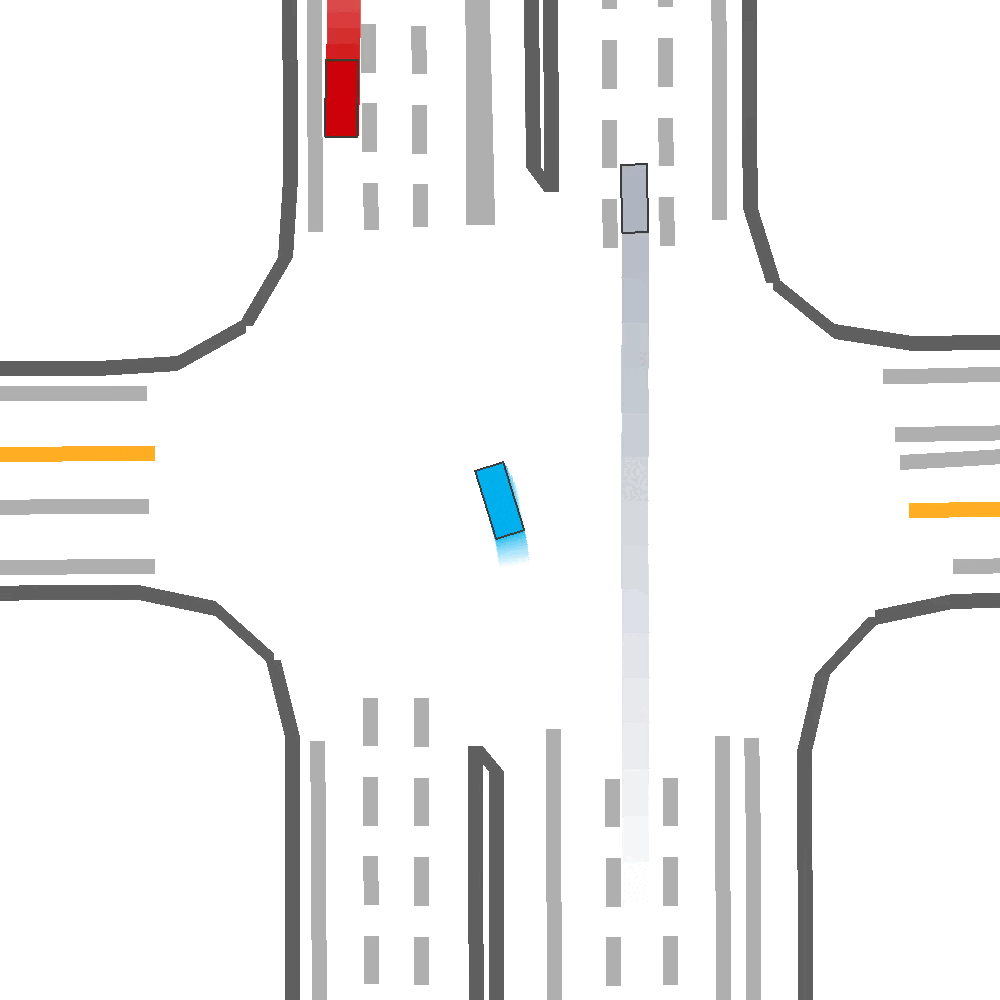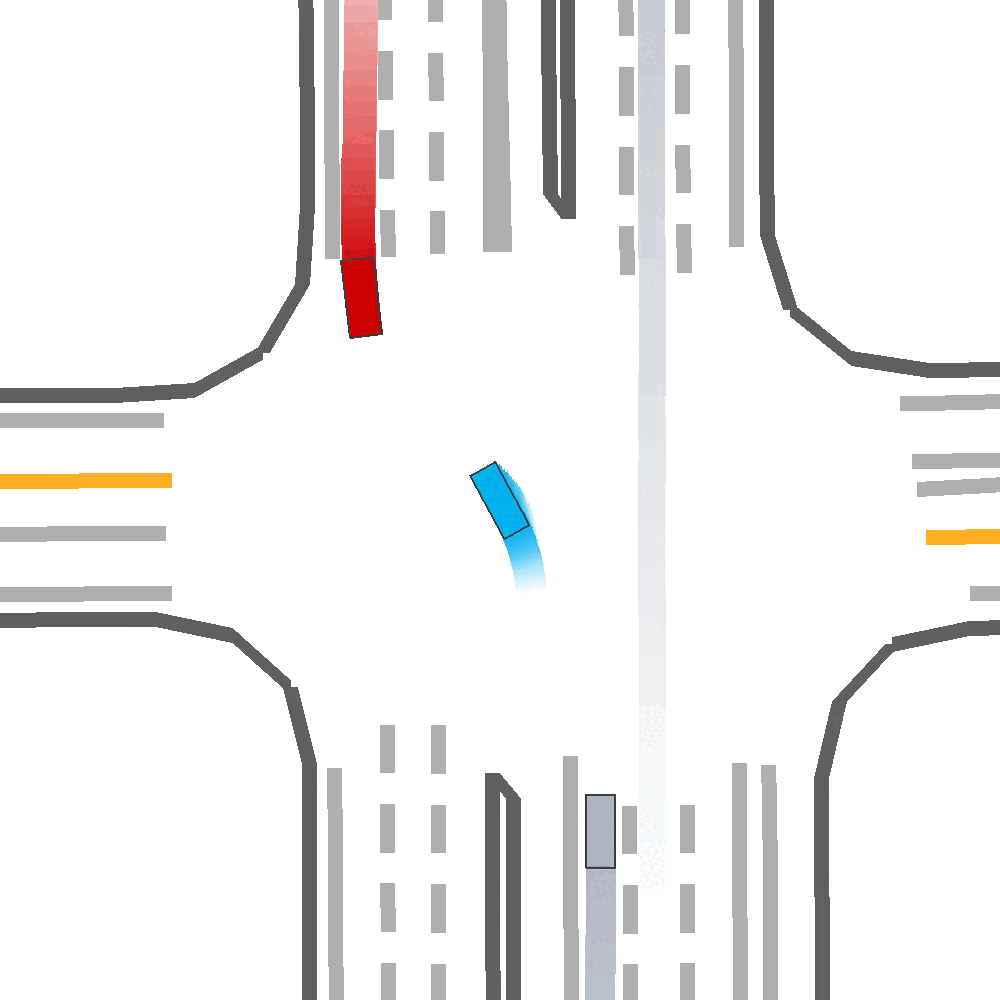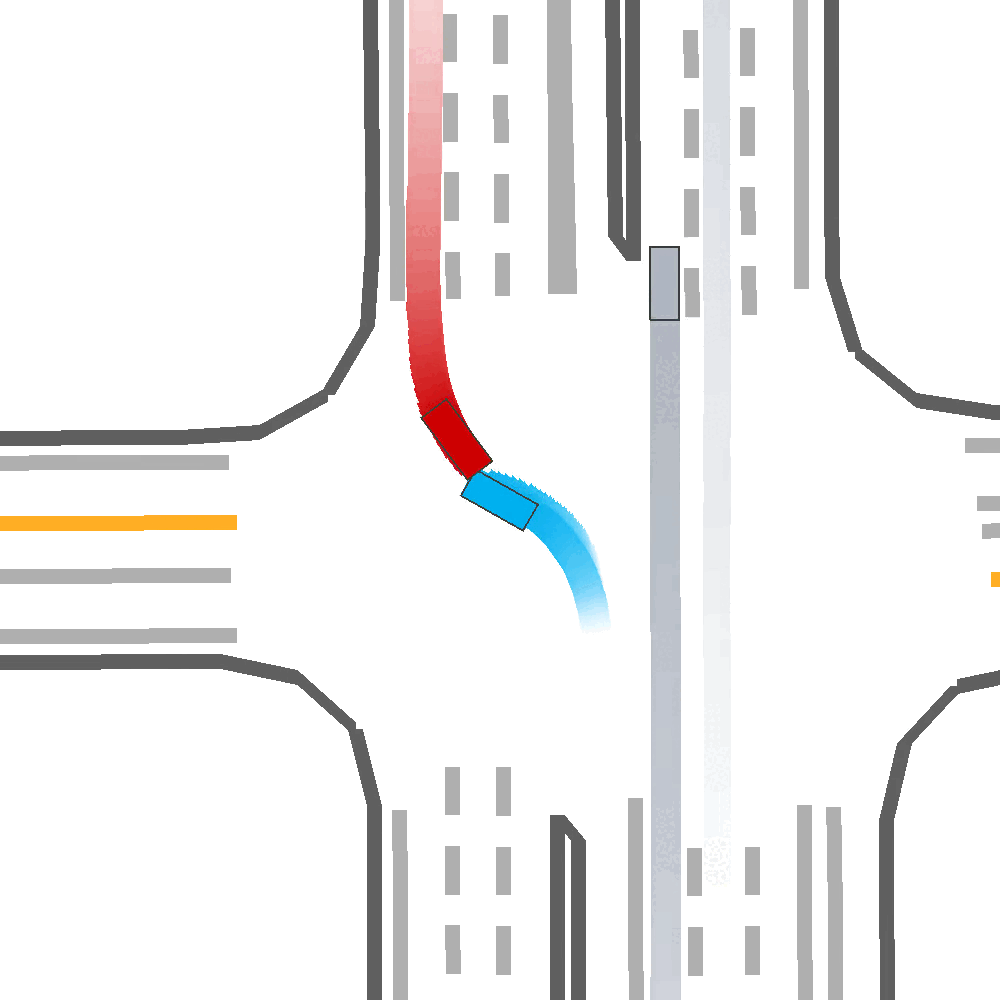
 Our Idea
Our Idea
To address these limitations, we propose a method for Skill-Enabled Adversary Learning (SEAL) which improves downstream ego behavior in closed loop training for safety-critical scenario generation.
SEAL introduces two novel components:
- A learned scoring function to anticipate how a reactive ego agent will respond to a candidate adversarial behavior.
- A reactive adversary policy that hierarchically selects human-like skill primitives to increase criticality and maintain realism.
Evaluation Fairness
Safety-critical scenario generation approaches should be evaluated not only in terms of induced criticality, but also in terms of behavior realism. However, recent works rely on evaluating ego policies leveraging their scenario generation approach, wherein safety-critical behavior is in-distribution. While this is informative for assessing ego performance, we argue that performance on challenging scenes is ultimately more important.
Our Idea
We create a realistic out-of-distribution evaluation setting leveraging recent work on scenario characterization to identify real (non-generated) safety-relevant scenarios.
Method
SEAL is a perturbation-based scenario generation approach which aims to increase criticality while also maintain scenario realism.
Like prior approaches, we utilize pre-trained trajectory prediction models to produce candidate future paths for an adversary agent to follow. However, instead of simply selecting the most critical predicted candidate based on heuristic functions, and have the adversary follow a predefined path, we aim to select paths more flexibly to enable reactive and human-like behavior.
To do so, we introduce two novel components: a learned selection function, and a adversarial skill policy.
Learned Score Function
Adversarial approaches often rely on heuristic functions that maximize criticality in order to select candidate adversarial trajectories. One such example is counting bounding-box overlaps.
To focus on safety-criticality more broadly, e.g., enforcing hard-braking and swerving maneuvers, instead of only collisions, we leverage a learned scoring function that balances two objectives when selecting among candidate adversary trajectories: closeness to collision as well as likelihood of anticipated deviation of an ego agent.
To learn such a score function, we build a dataset of simulated outcomes between the ego-agent and the adversary, and obtain ground truth collision and deviation measures (equations (1) and (2) in our paper). Then, we train a neural network to predict these values for a rollout yet to happen.
Adversarial Skill Learning
SEAL operates via an adversarial skill policy, which observes and acts closed-loop alongside the ego agent, to reactively roll-out hierarchical “skills”, that are useful to an adversary while still being human-like.
We train two Variational AutoEncoder (VAE) networks to to learn to reconstruct demonstrated adversarial (e.g., collision or near-misses) and benign (e.g., avoiding collisions while staying on road) skills.
The adversarial agent, leverages these policies to select skills which are likely to lead to a safety critical outcome, while also being human-like thereby improving behavior realism.
Results
Ego Policy Training
We evaluate SEAL primarily by examining it’s effectiveness when used as a form of data augmentation, during closed-loop training of an ego policy. Importantly, we assess trained policies on real WOMD, out-of-distribution scenarios from SafeShift
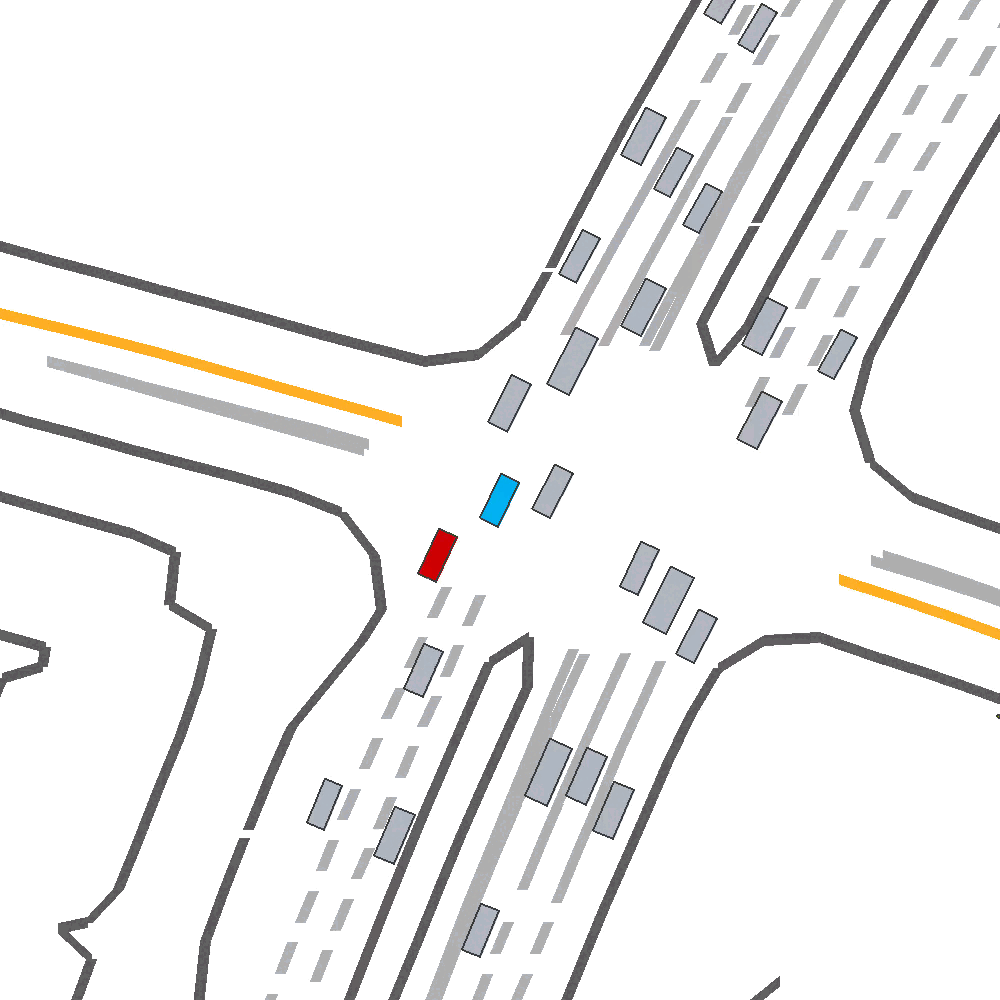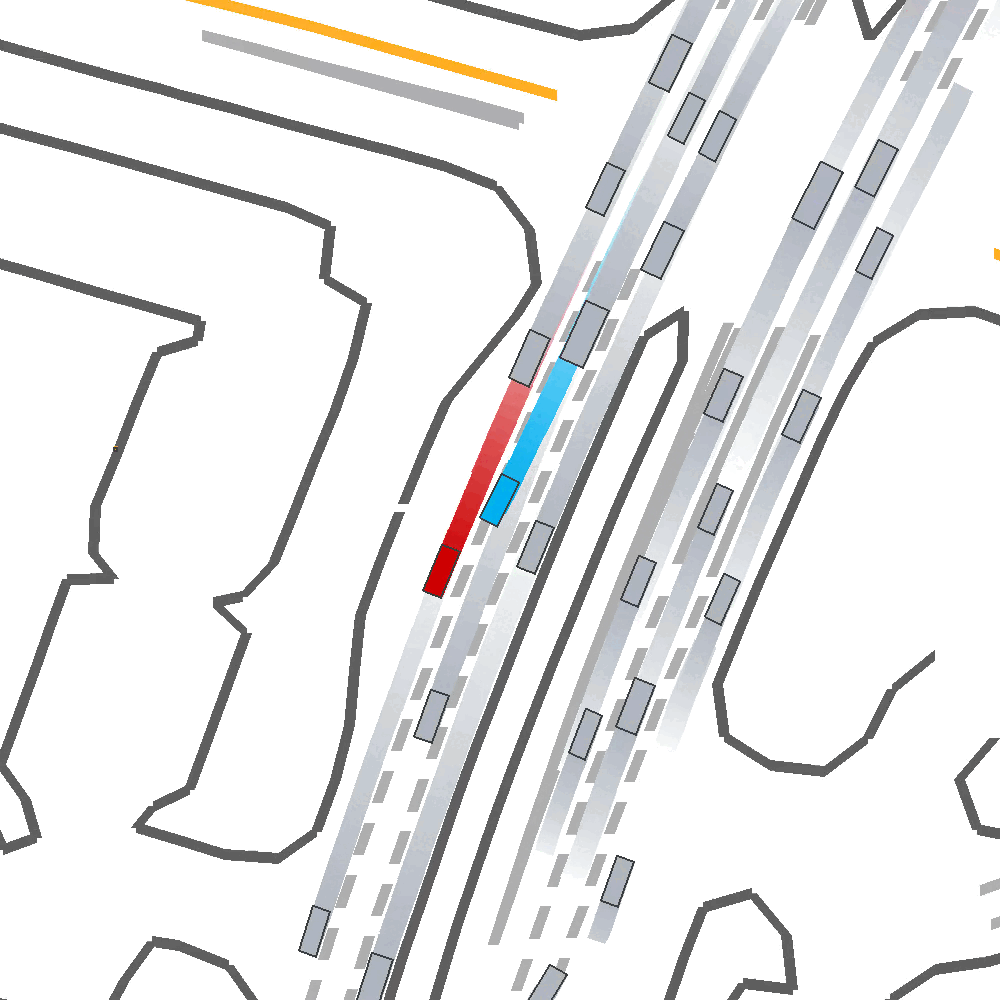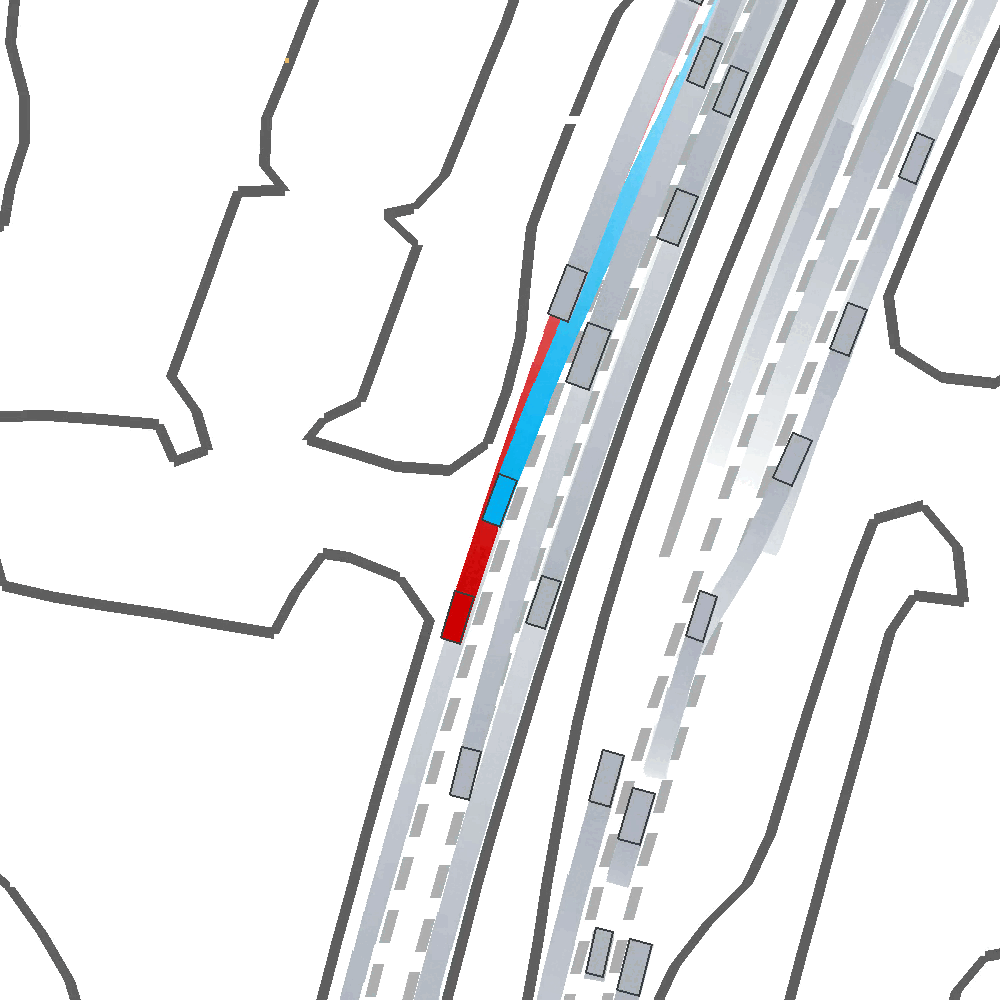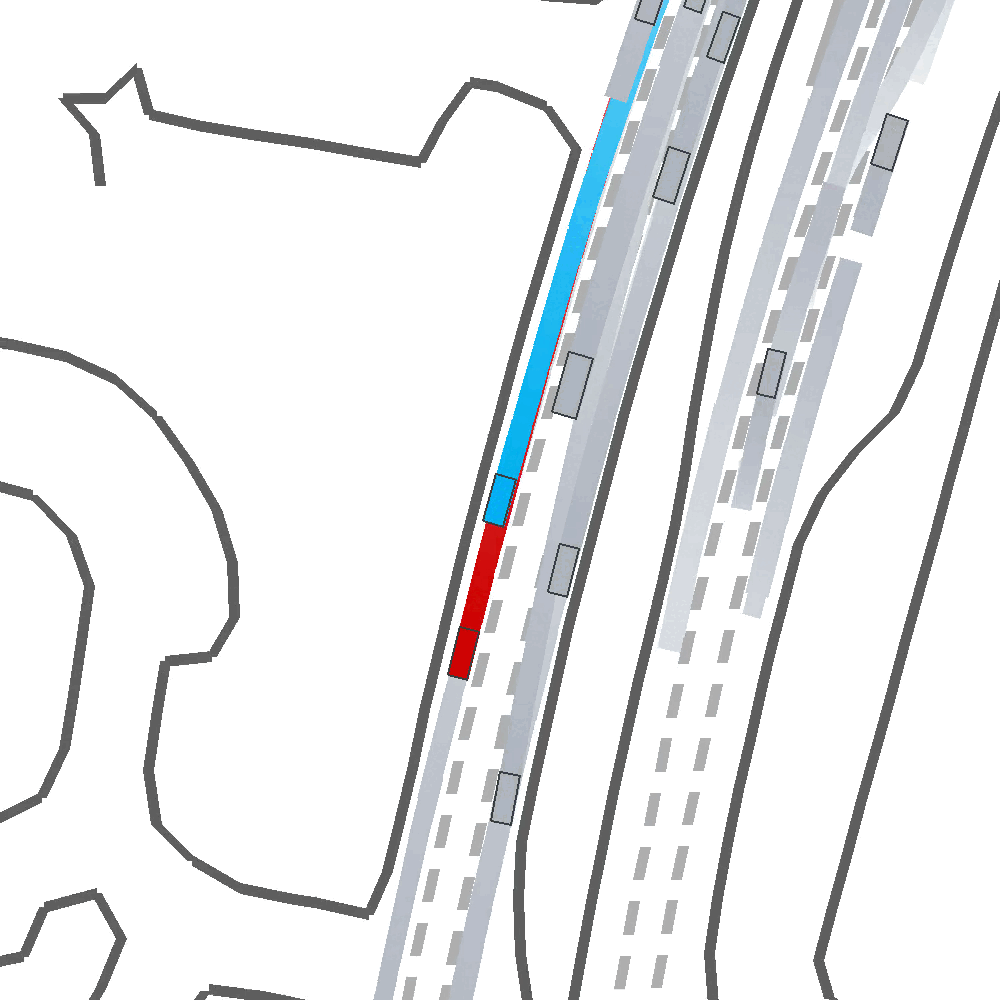
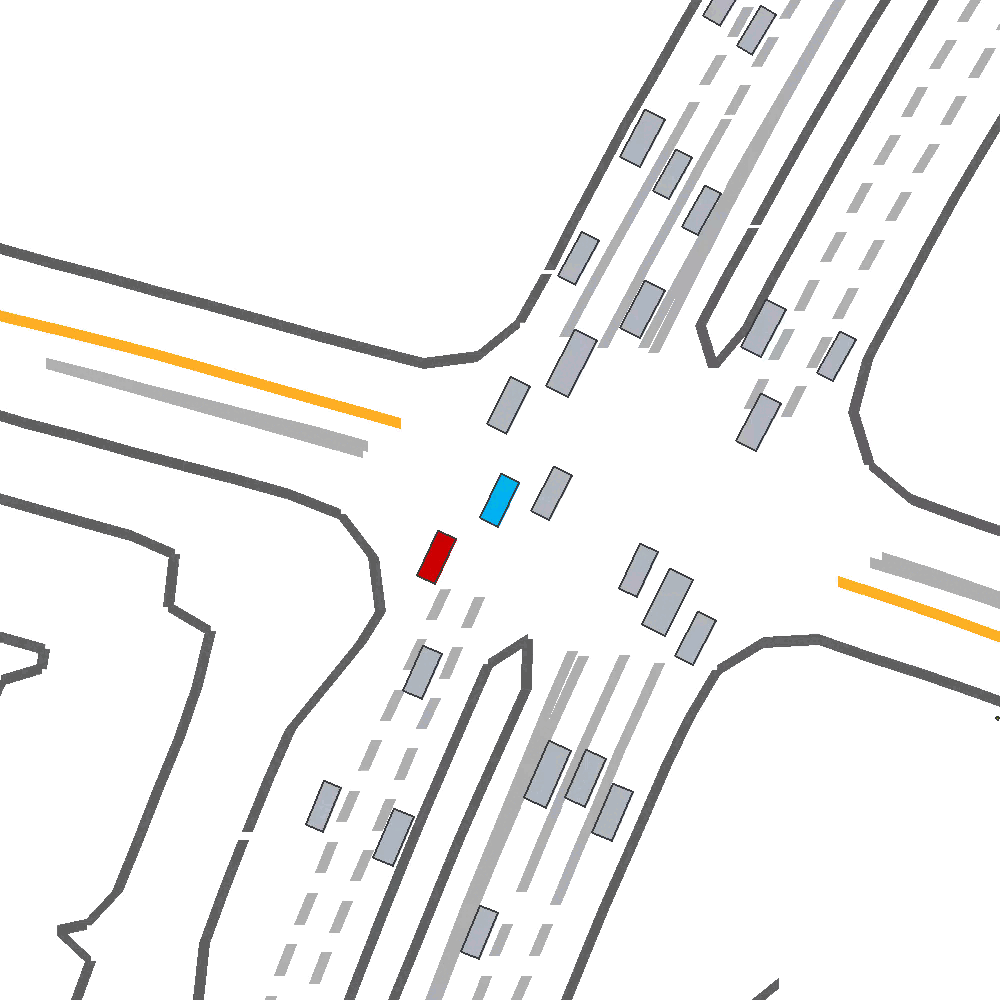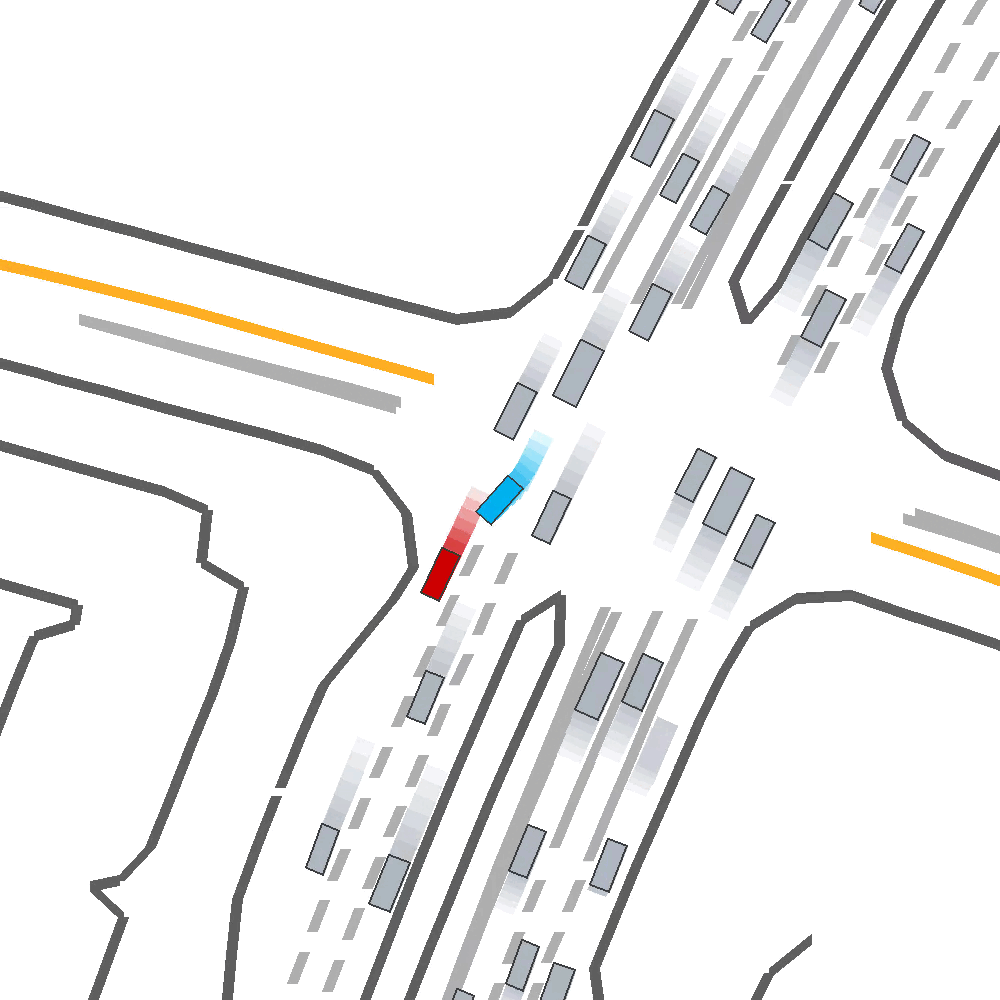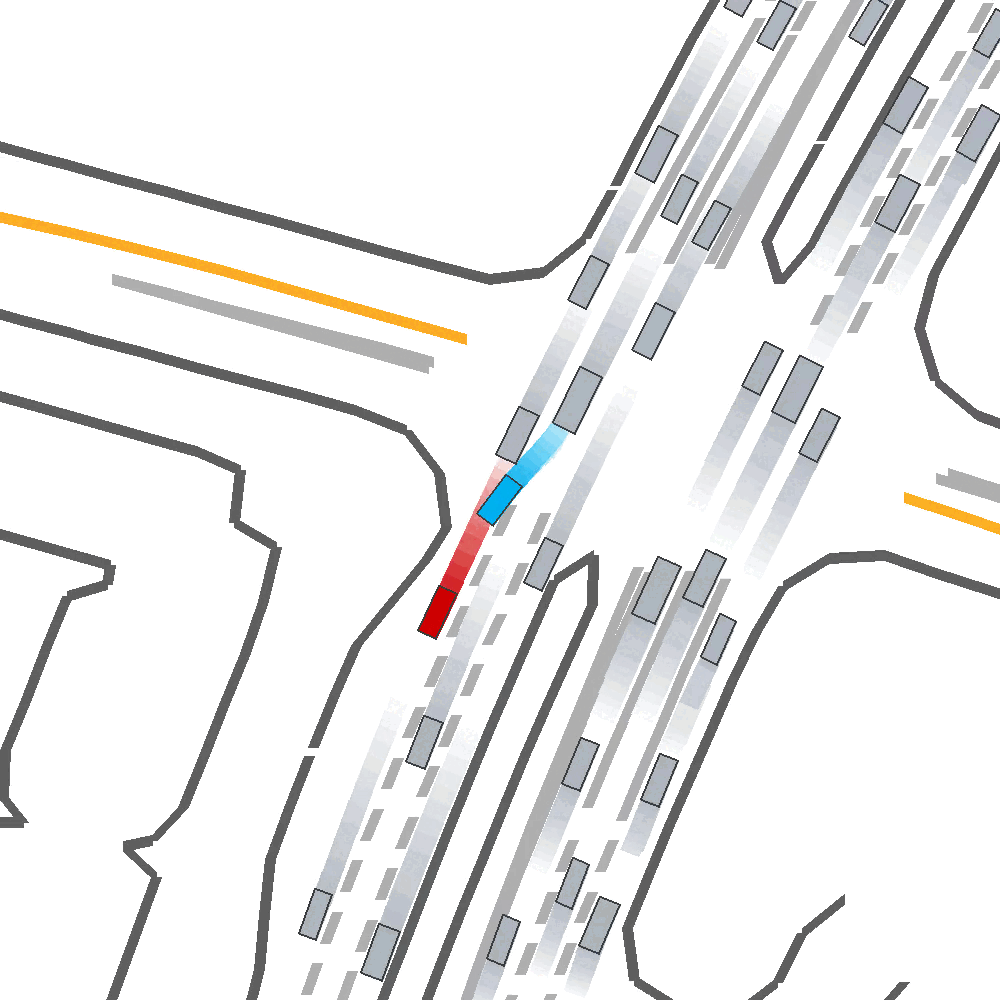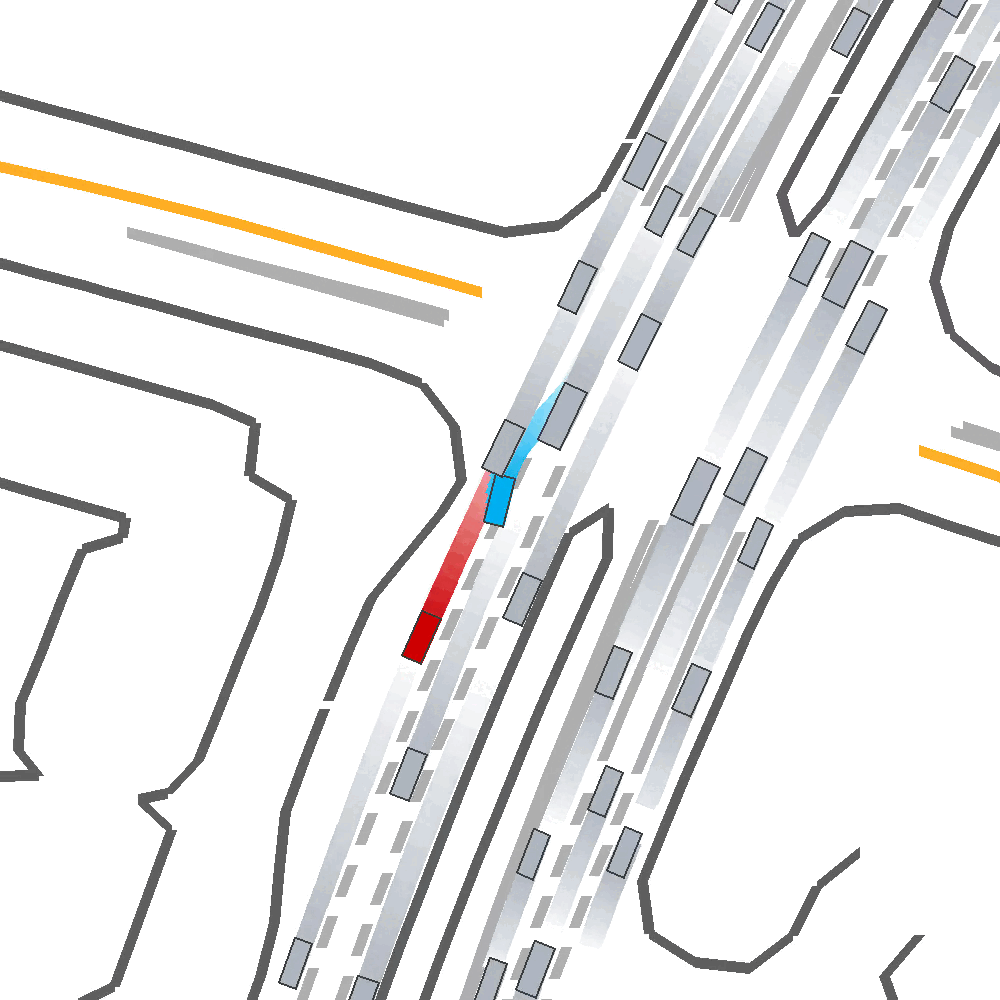
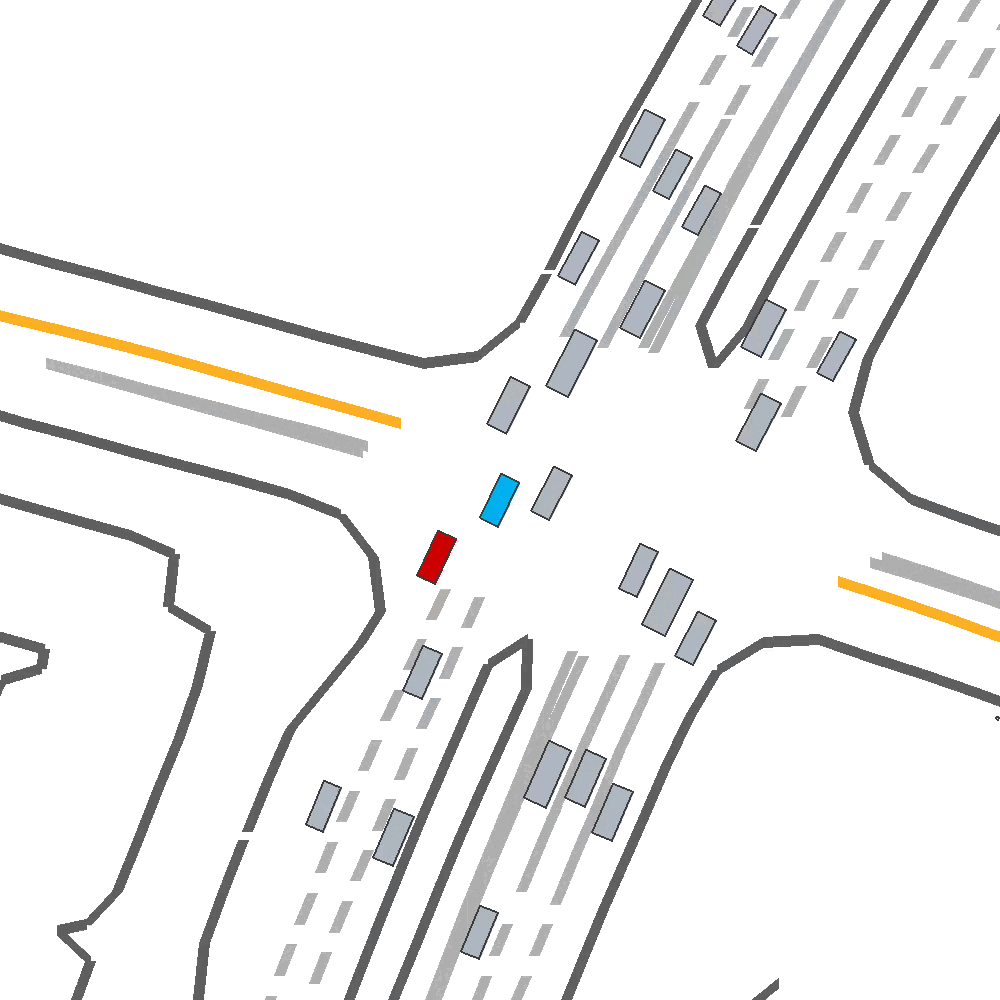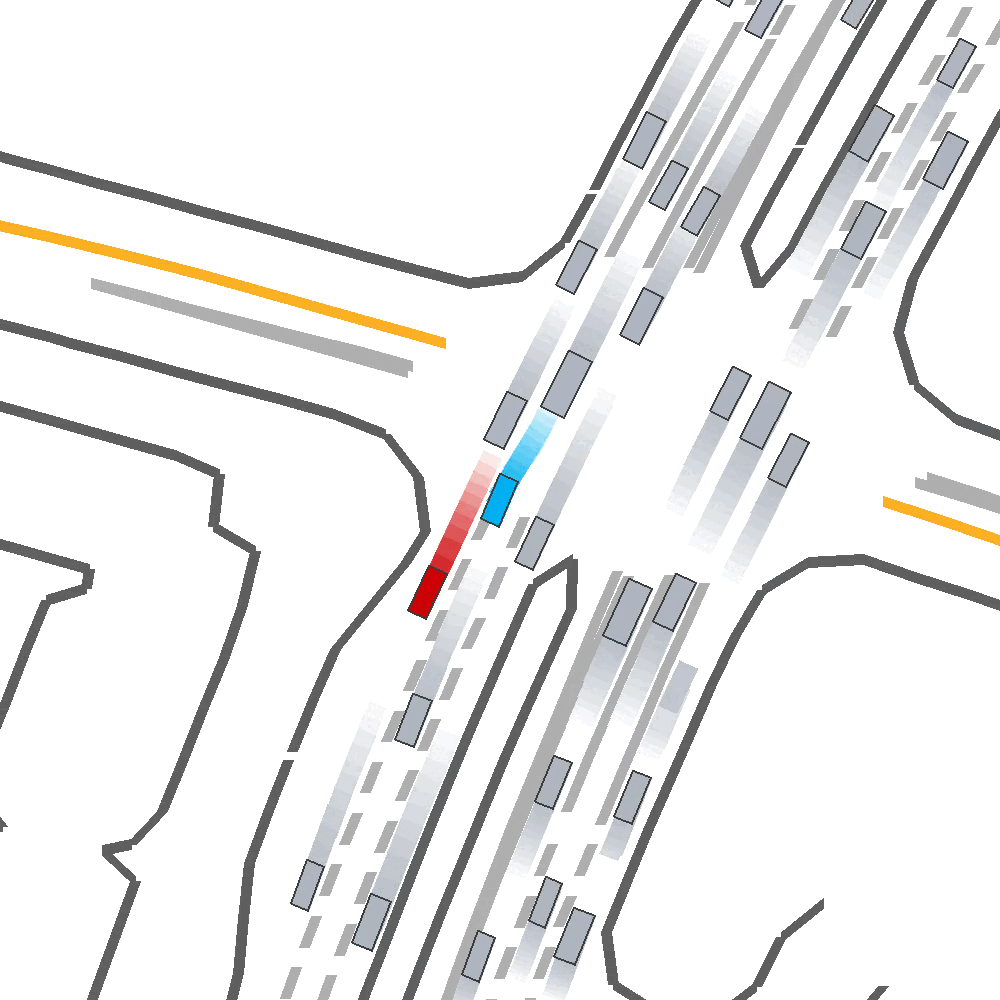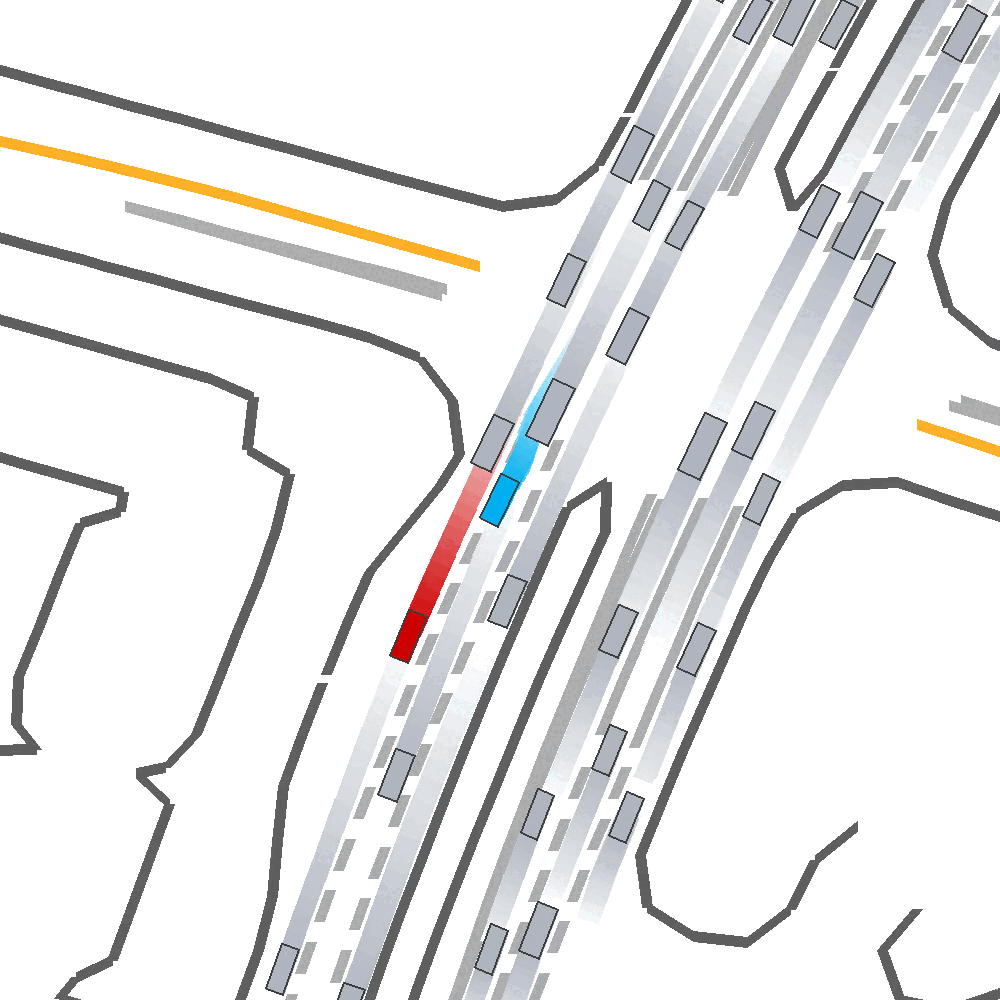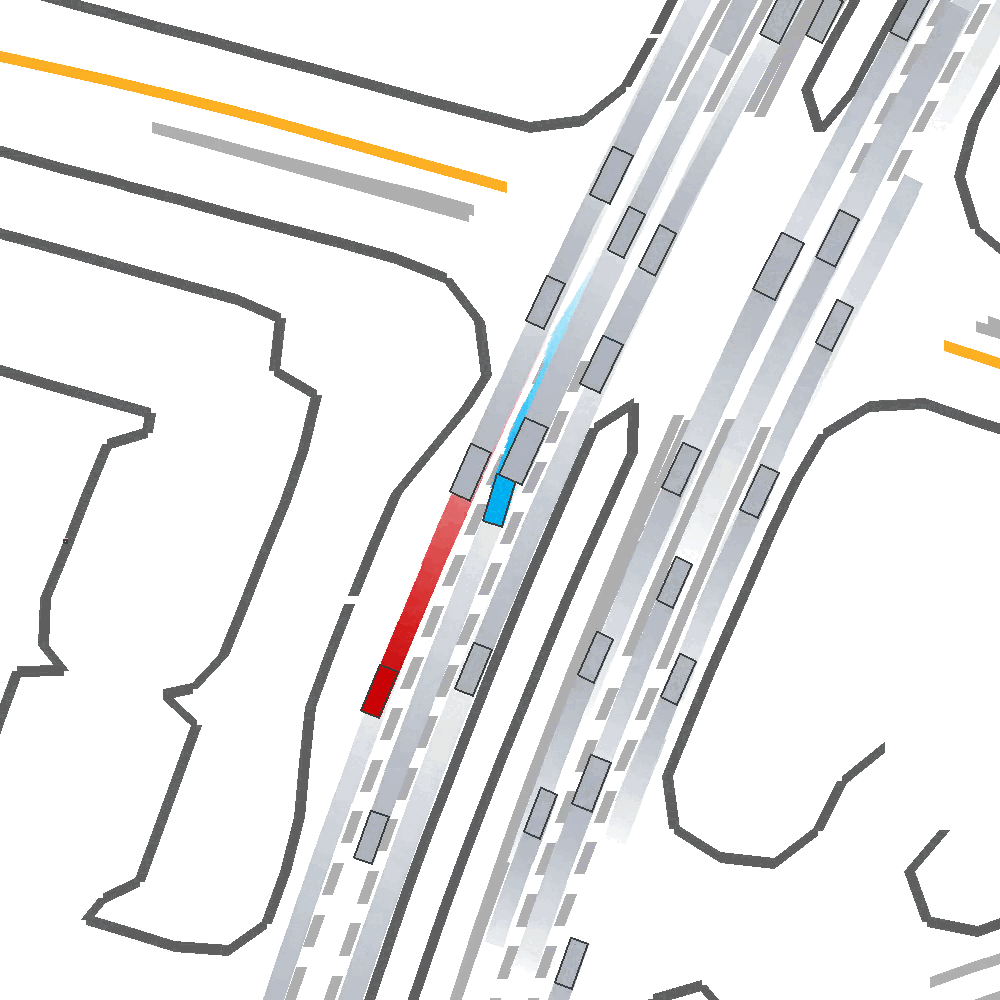
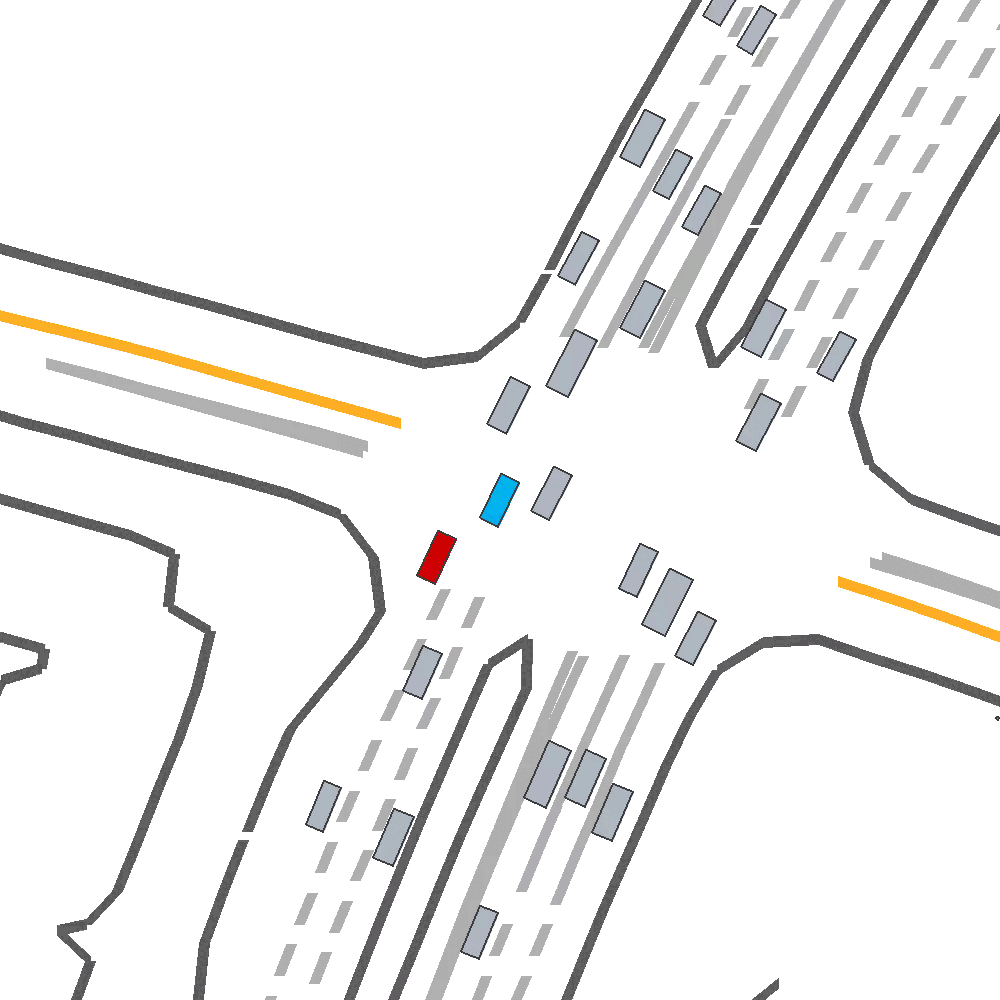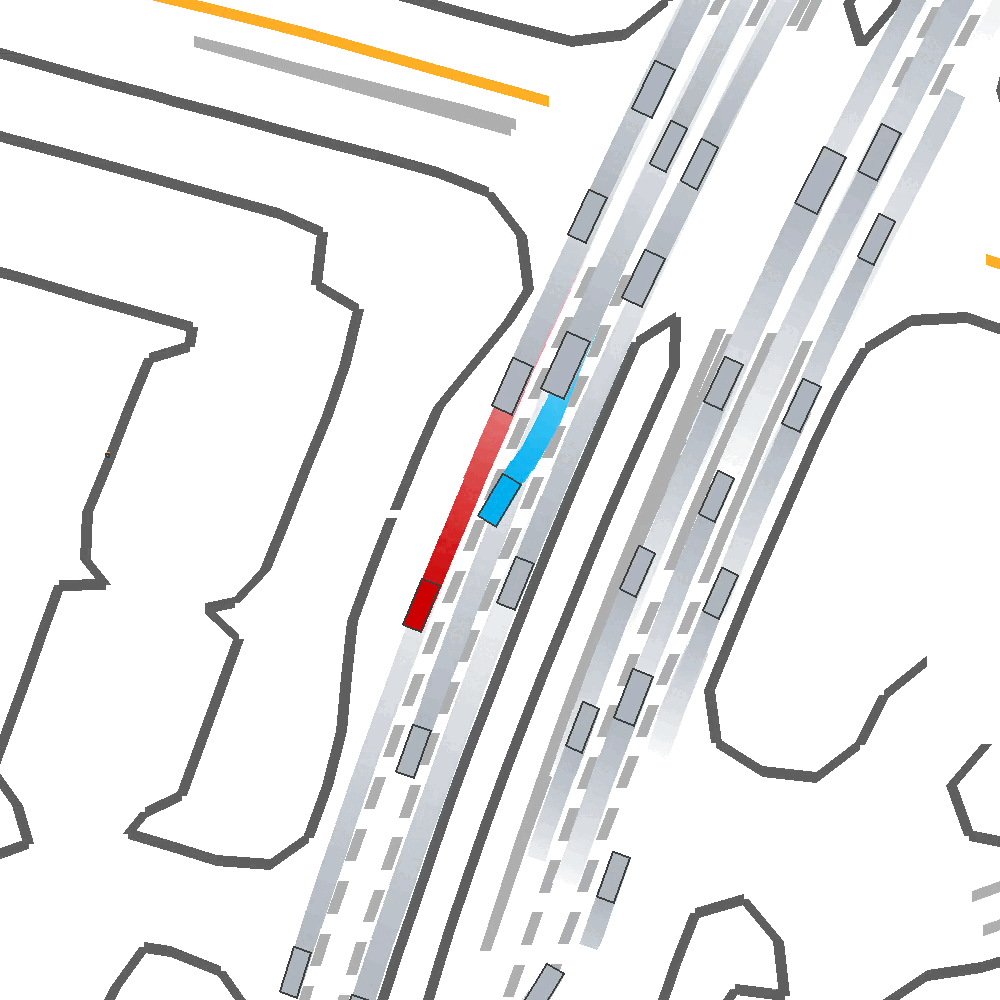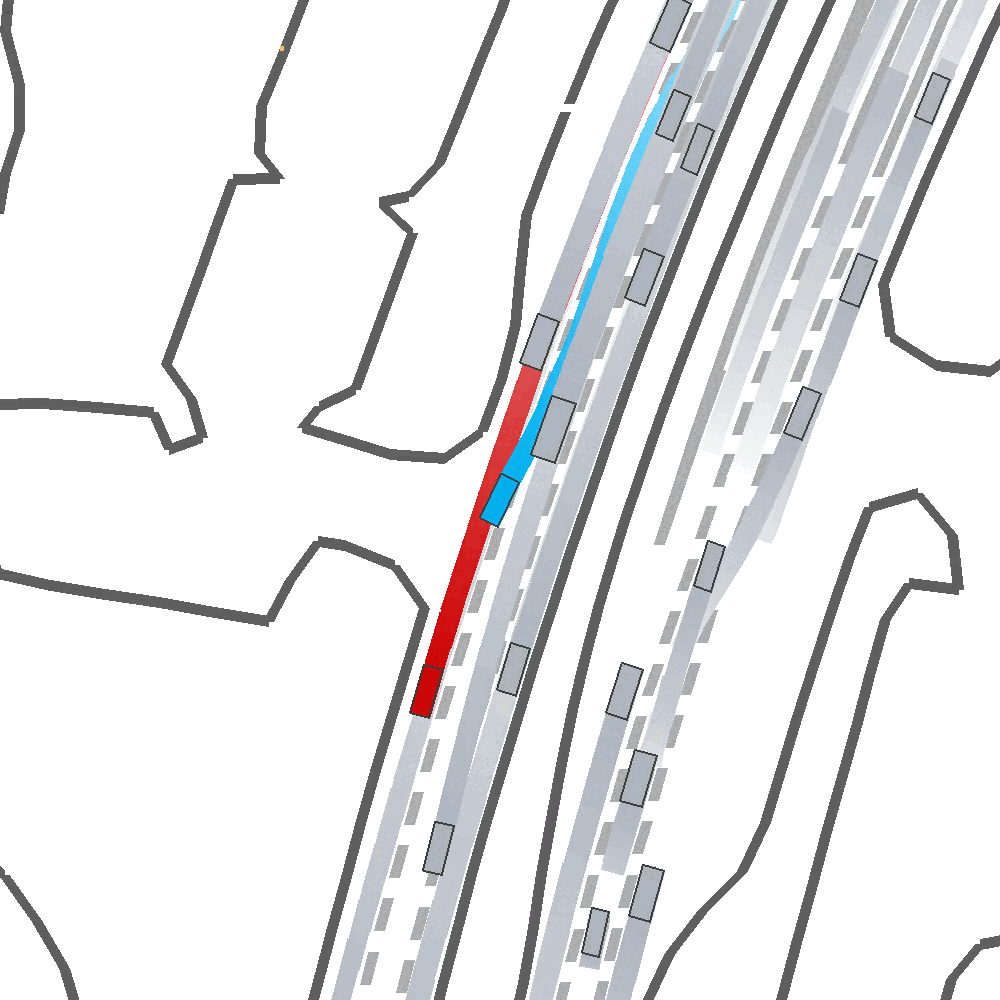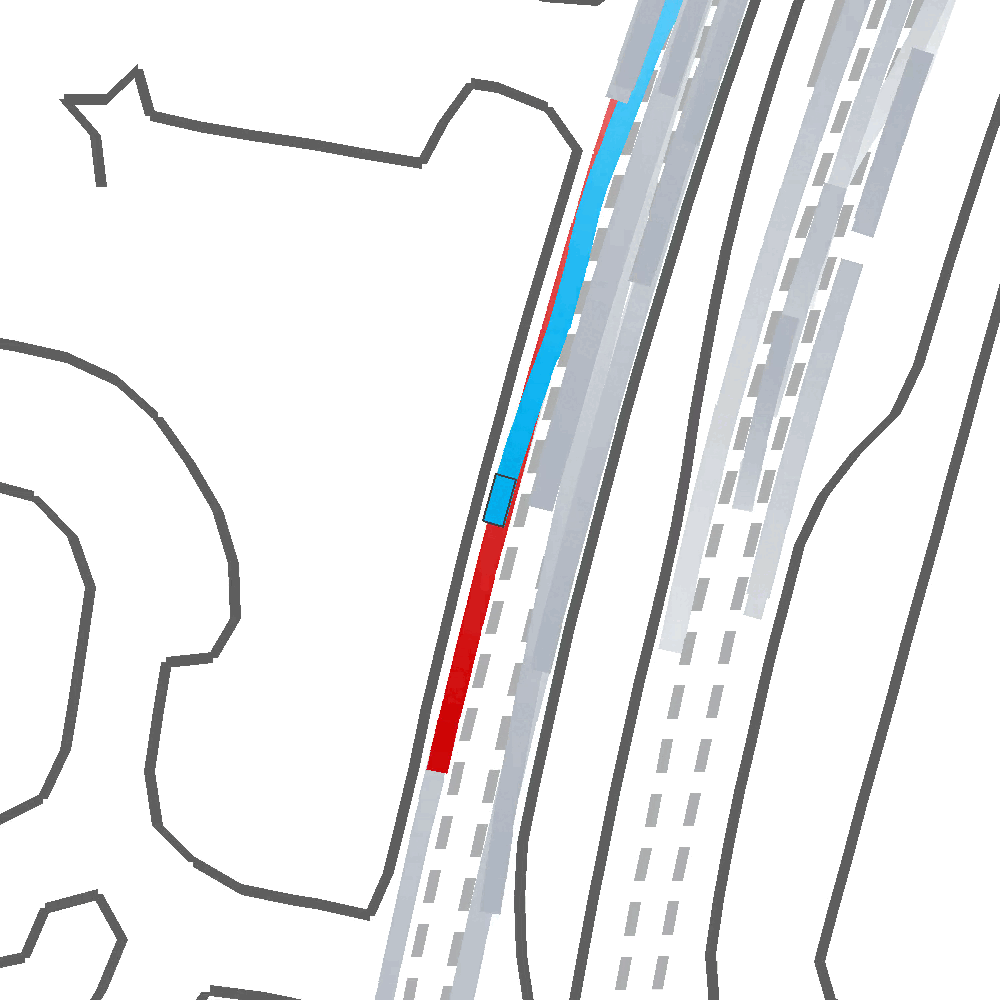
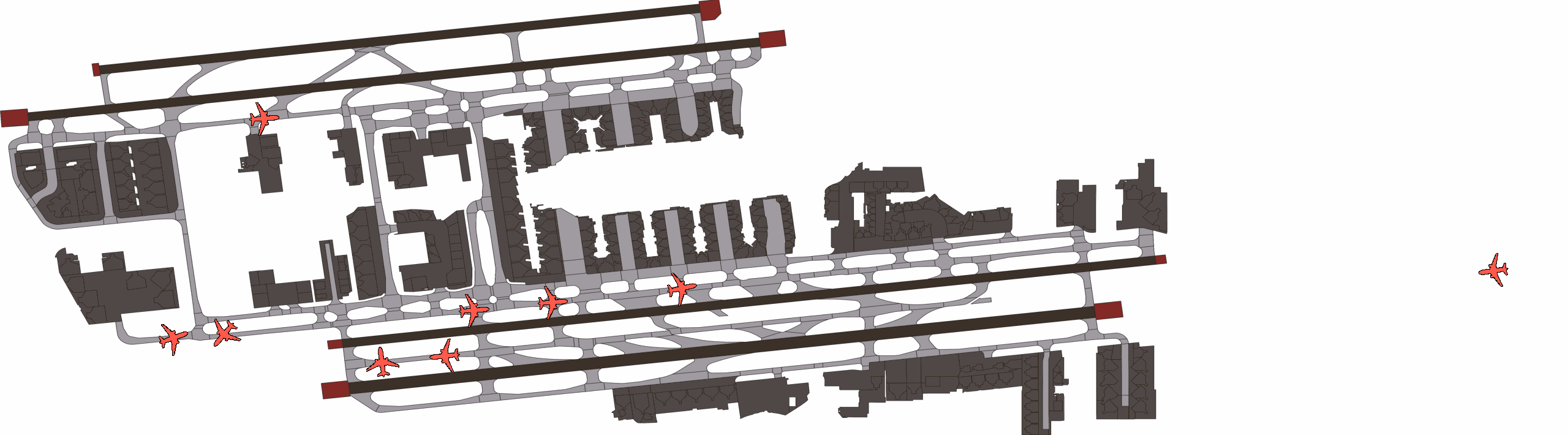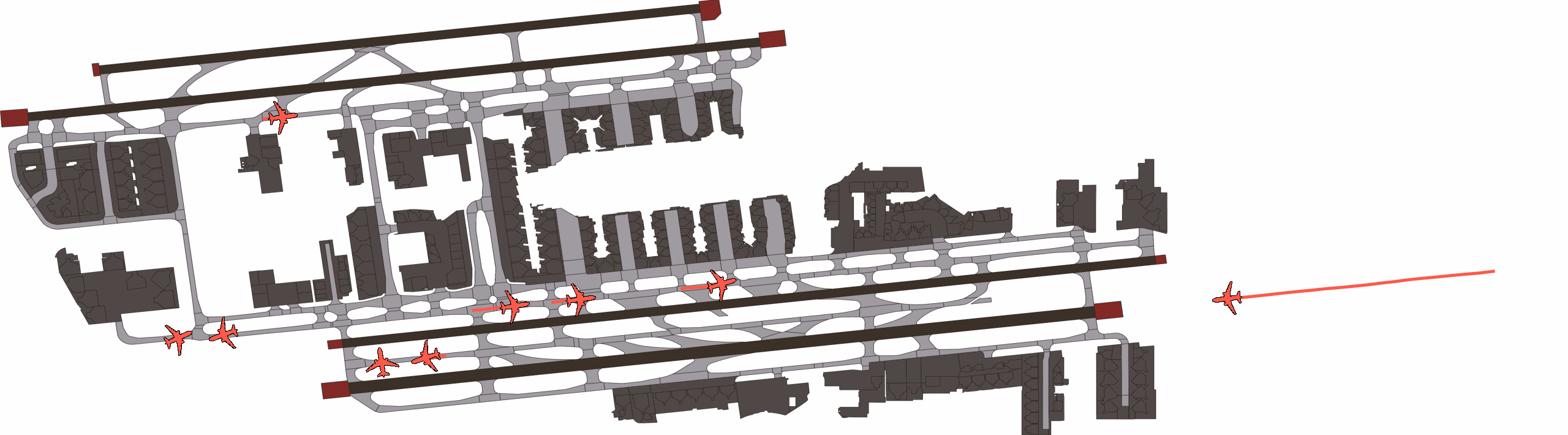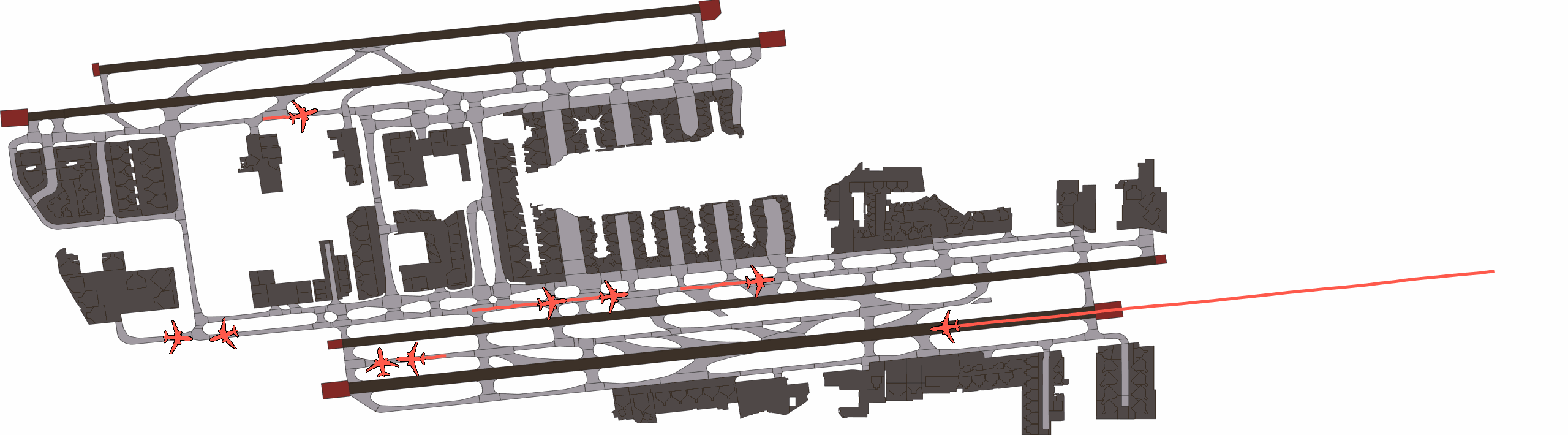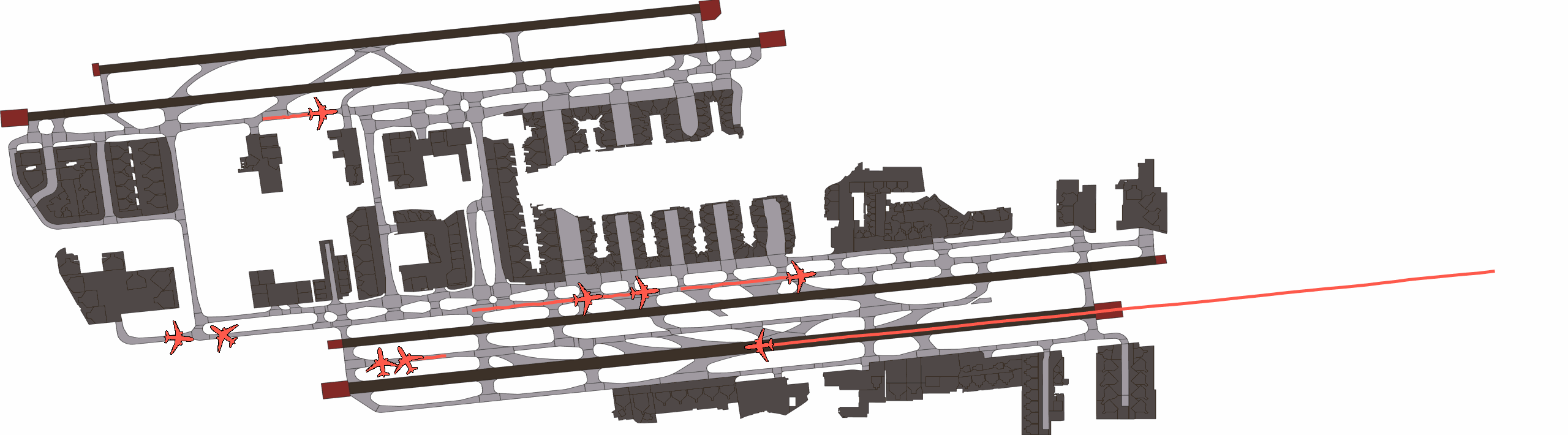
Qualitatively, we show an example of CAT and GOOSE-trained policies being insufficiently reactive to the challenging, real-world scenario; while the SEAL-trained policy is able to navigate successfully.
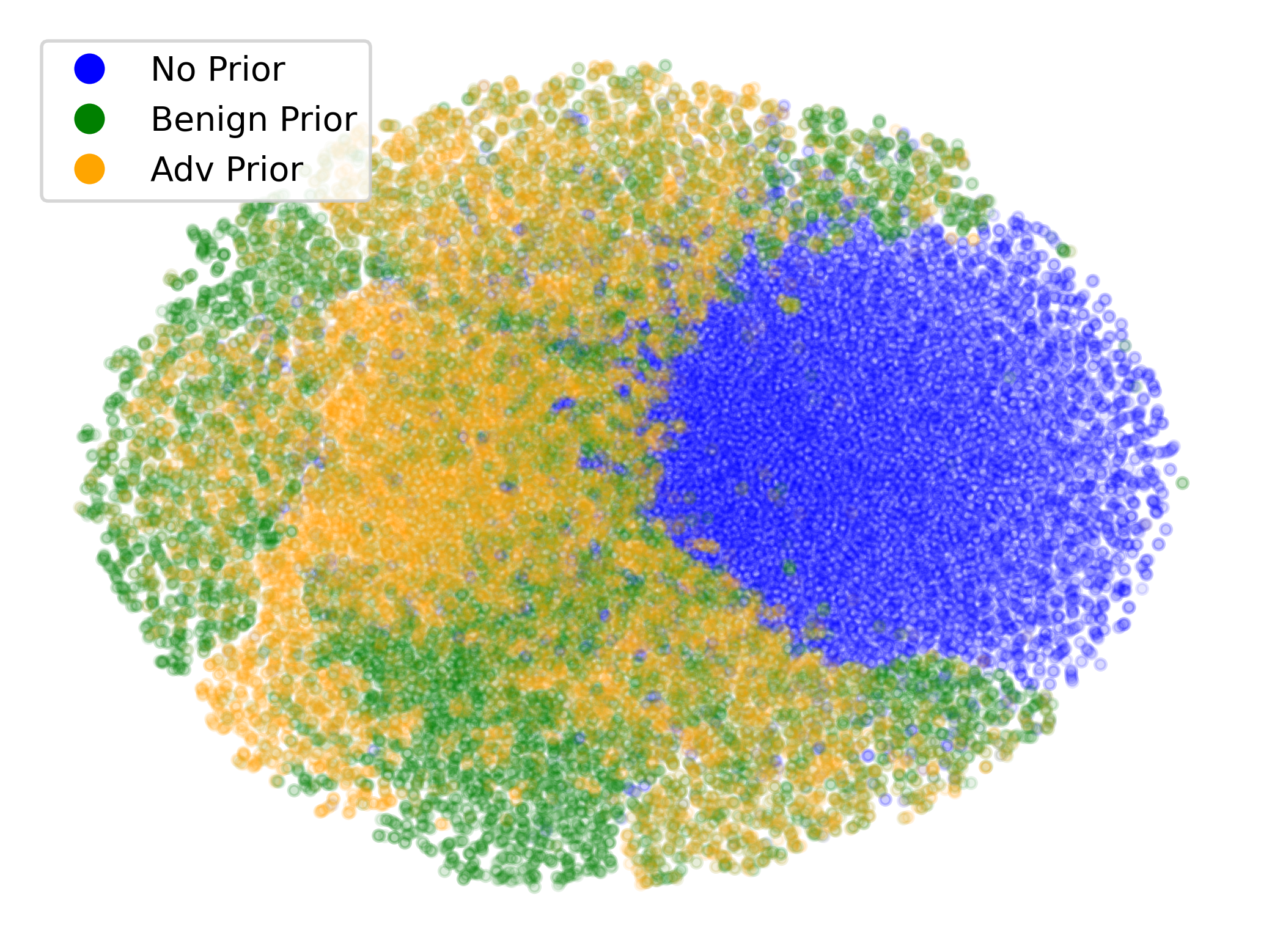
SEAL-generated Scenario Quality
We assess scenario generation quality by examining realism, in the form of Wasserstein distance to real-world adversarial behavior.
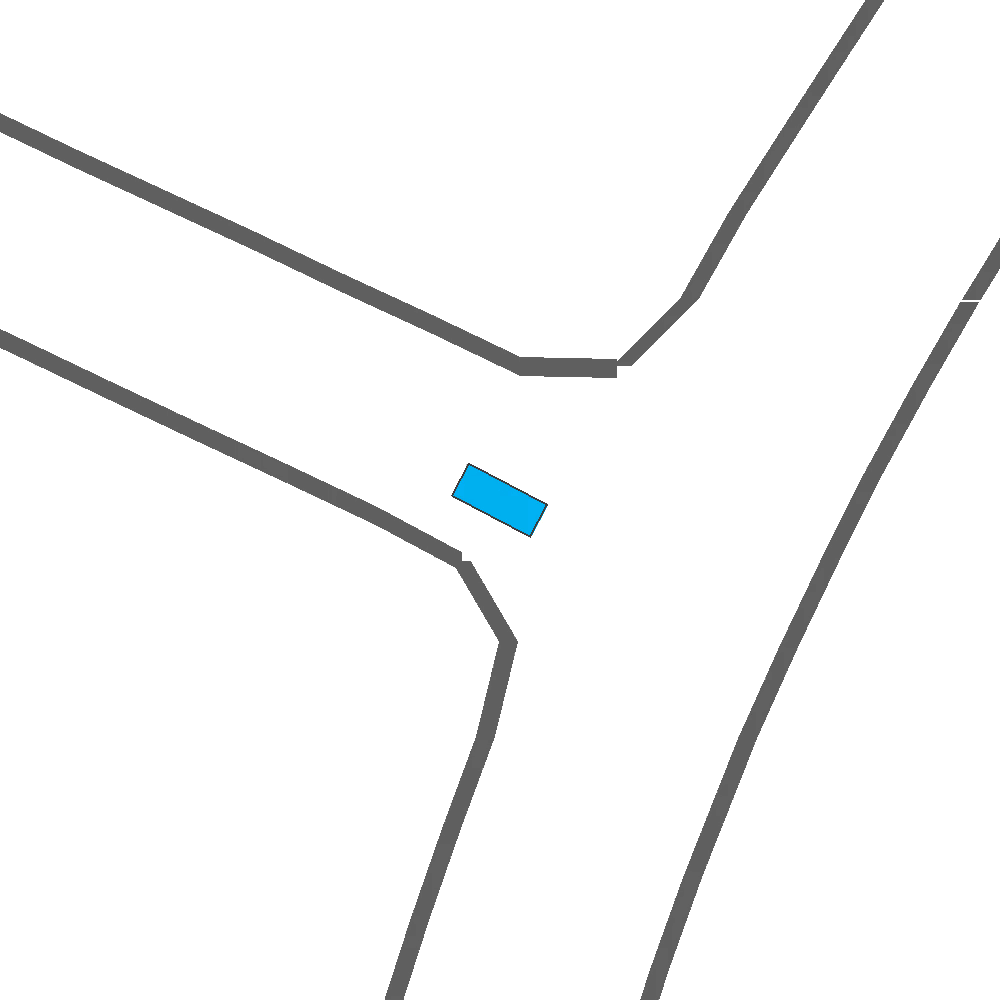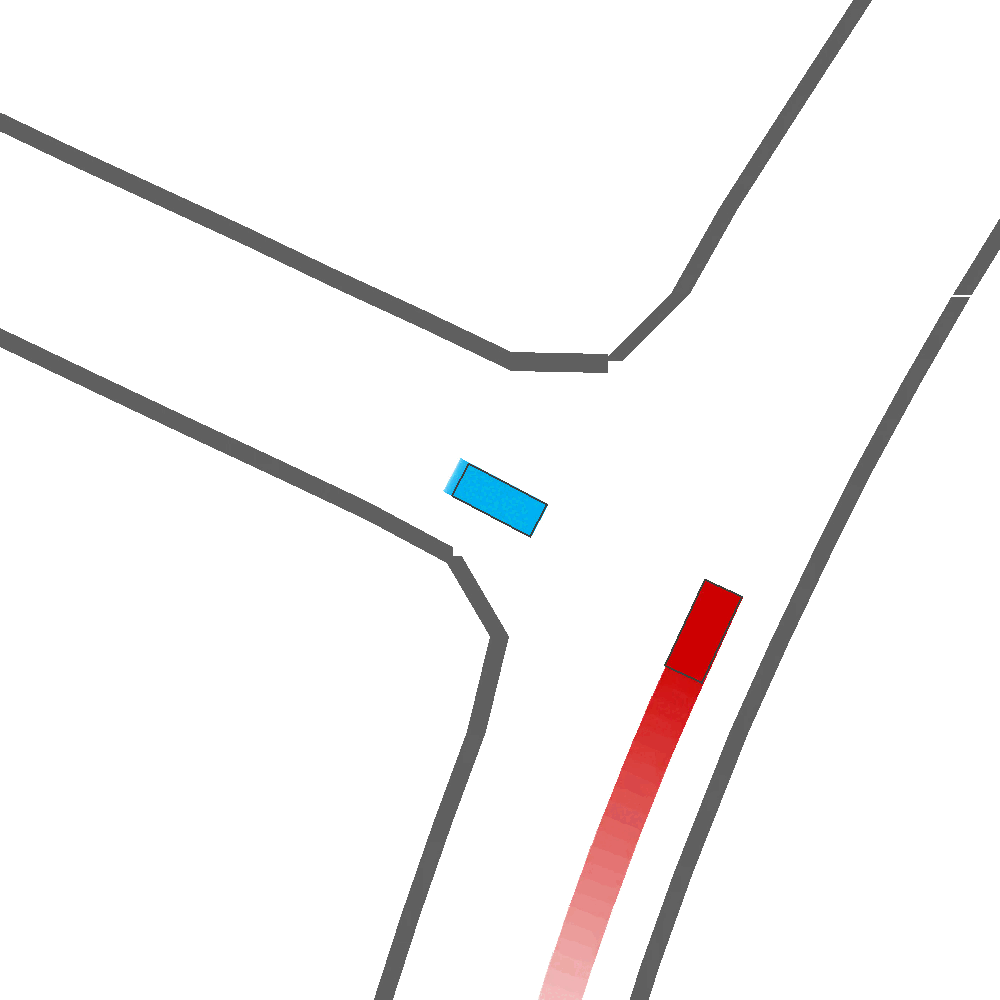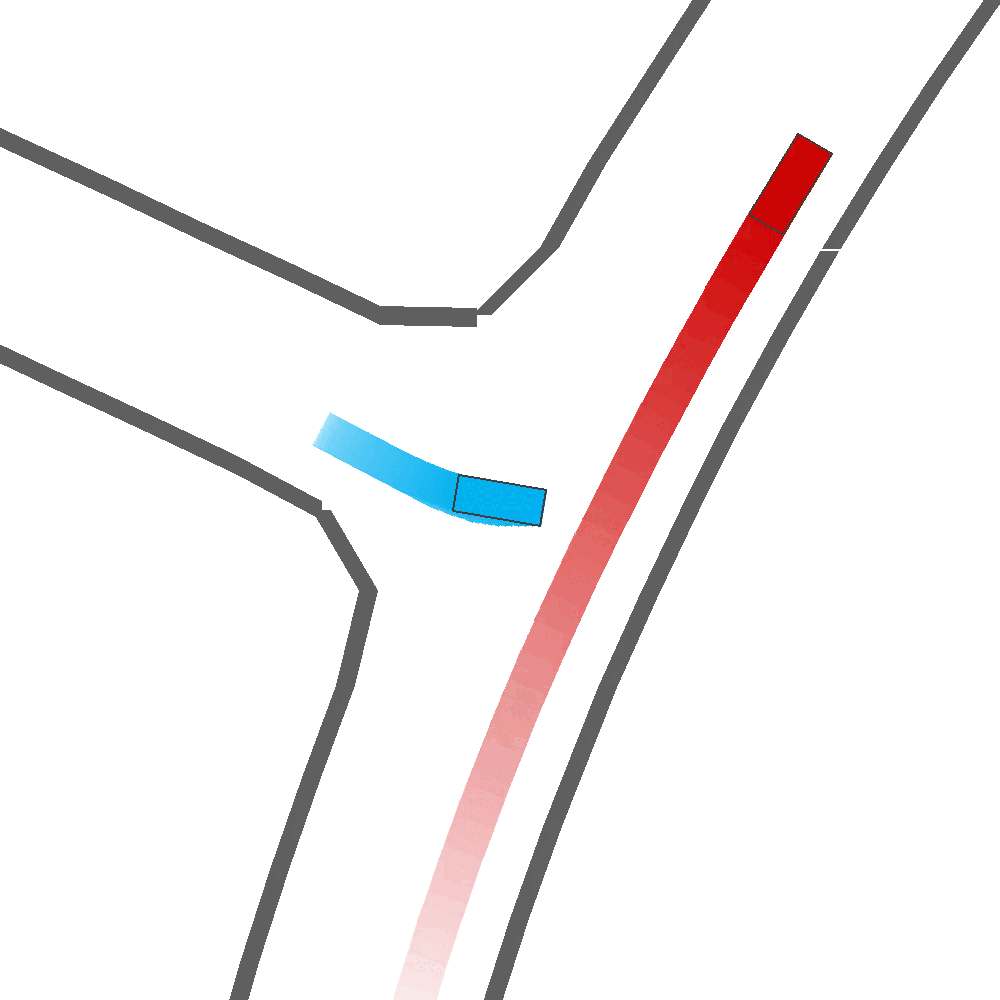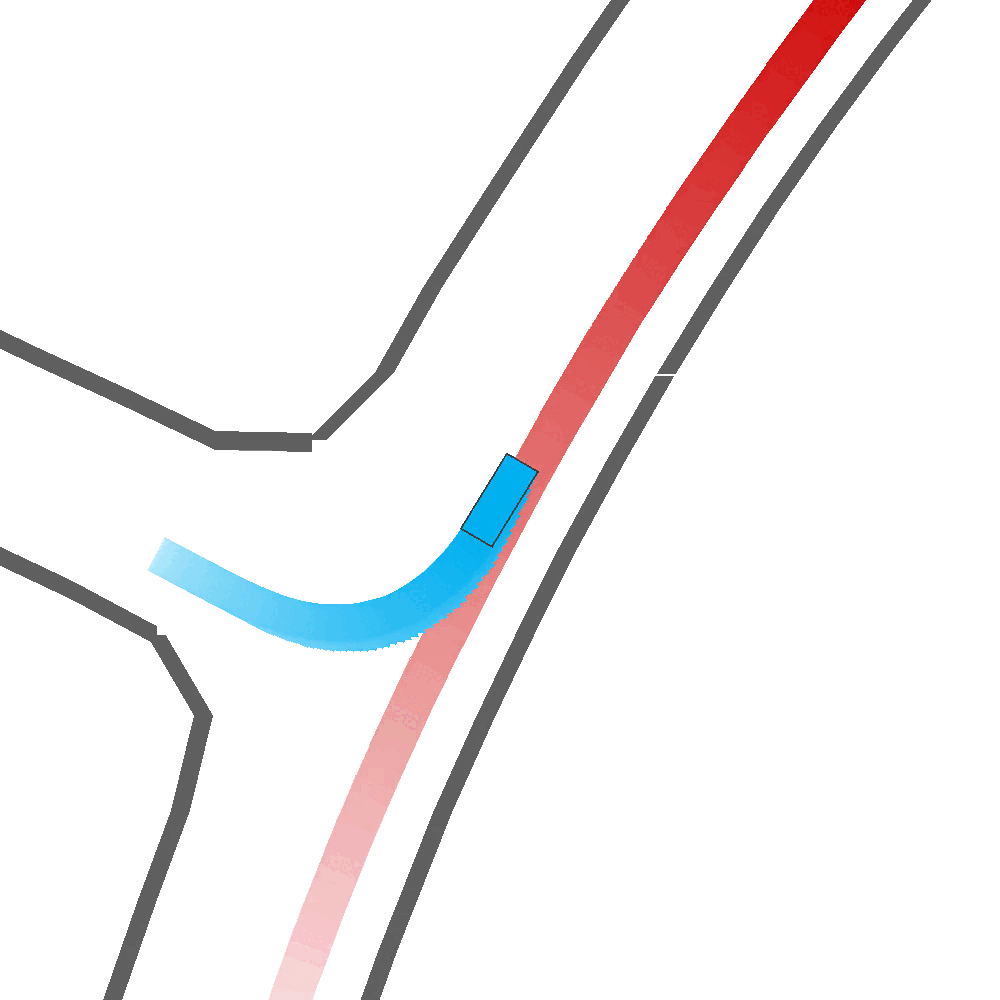
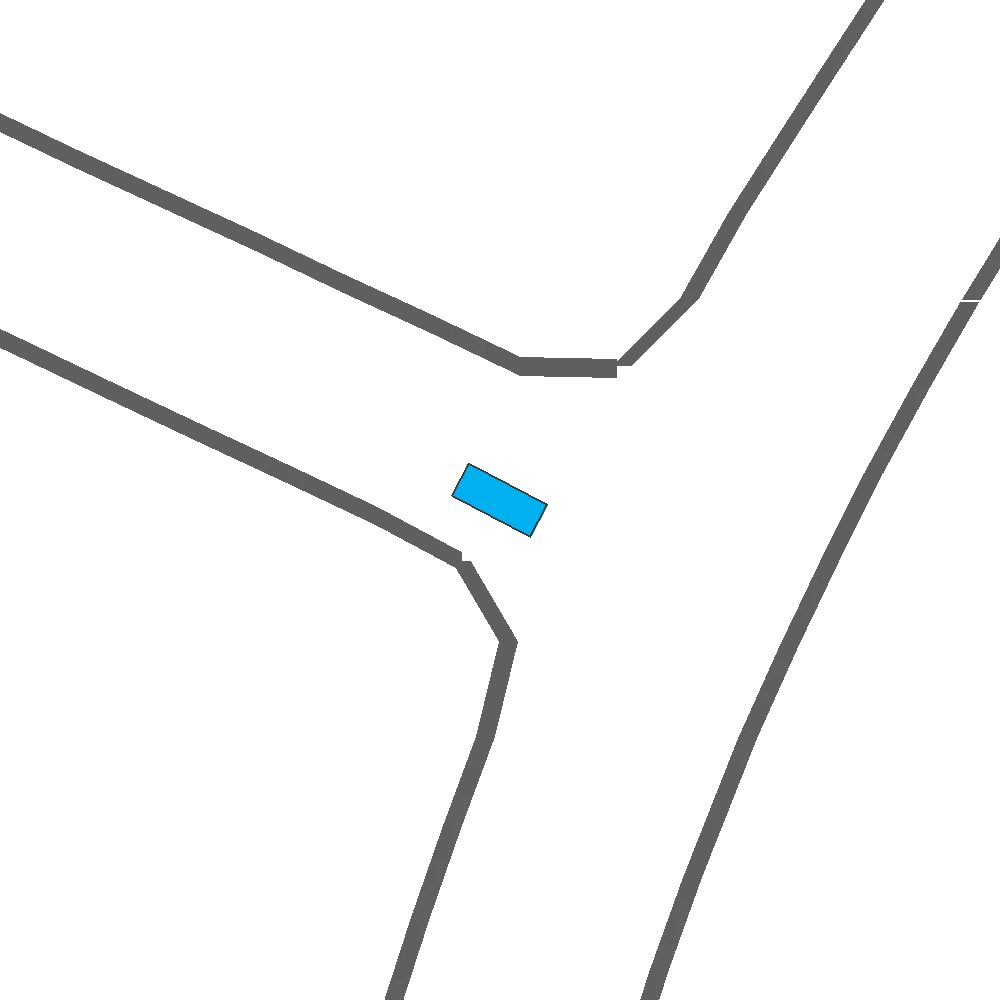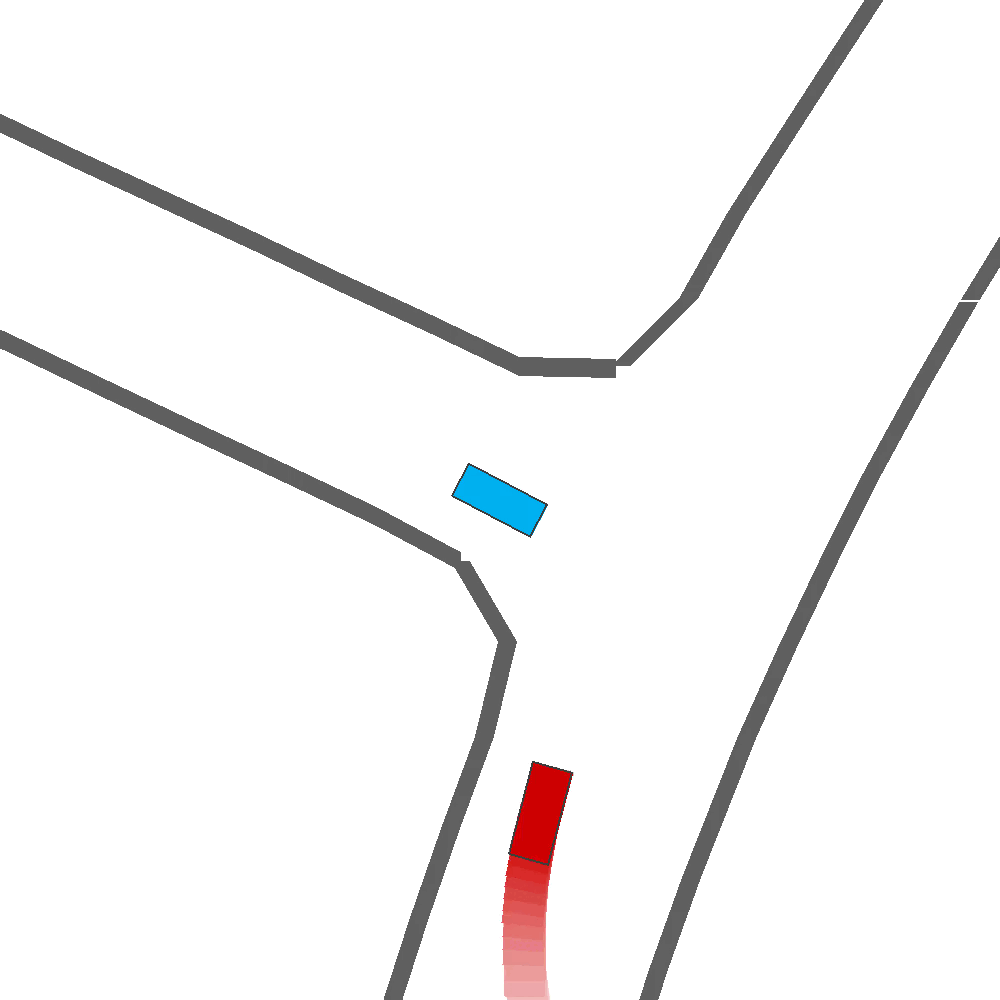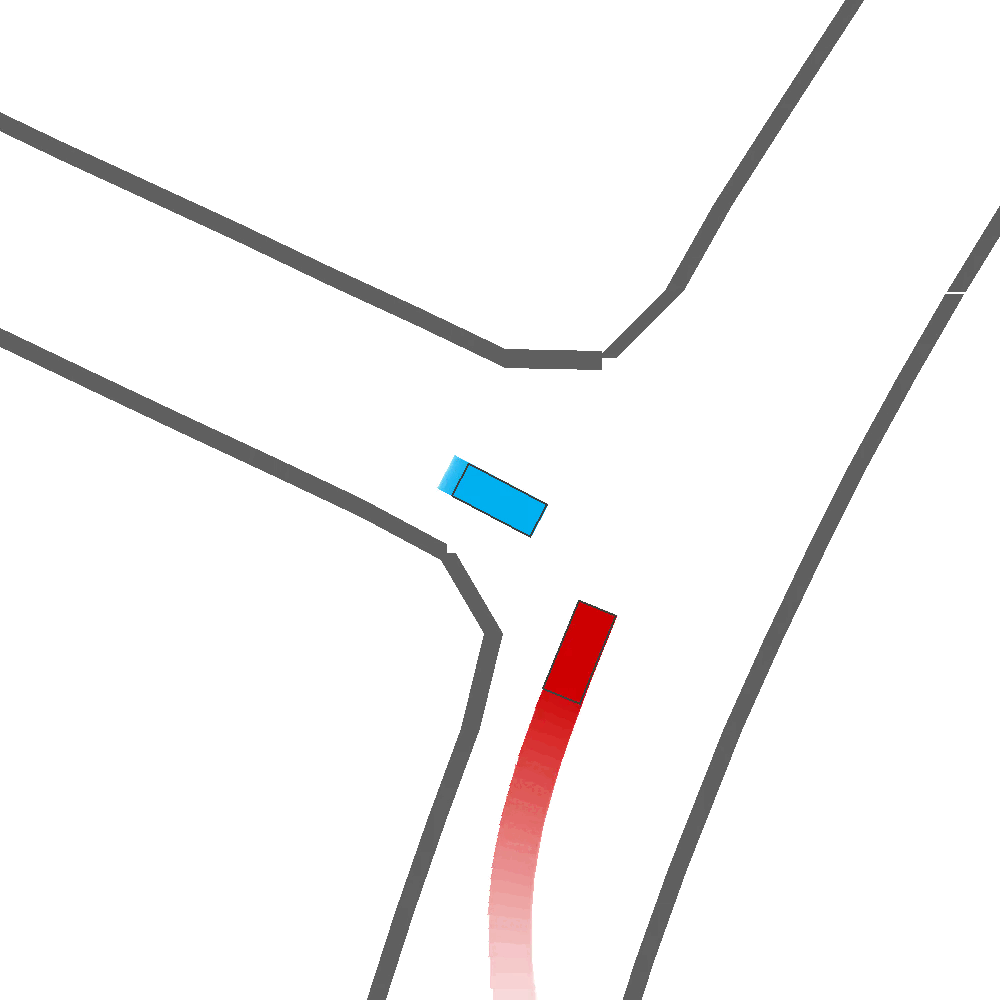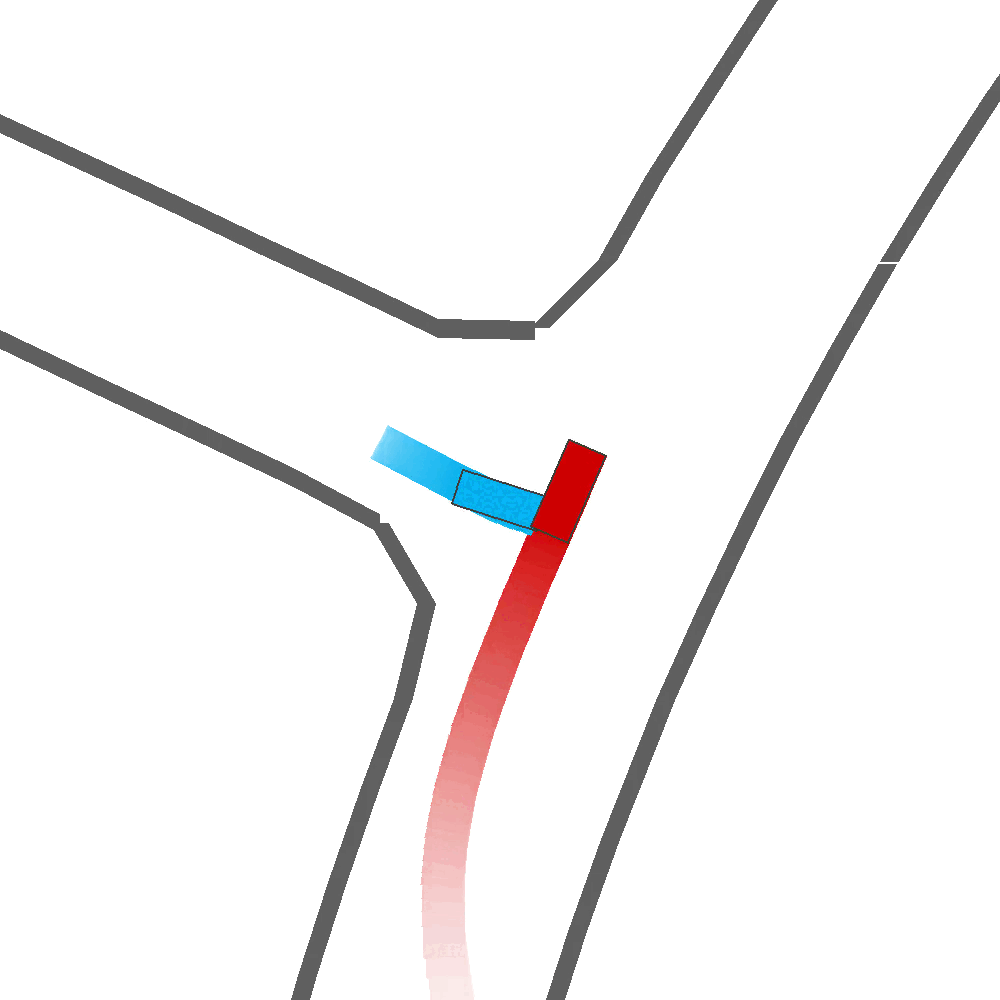
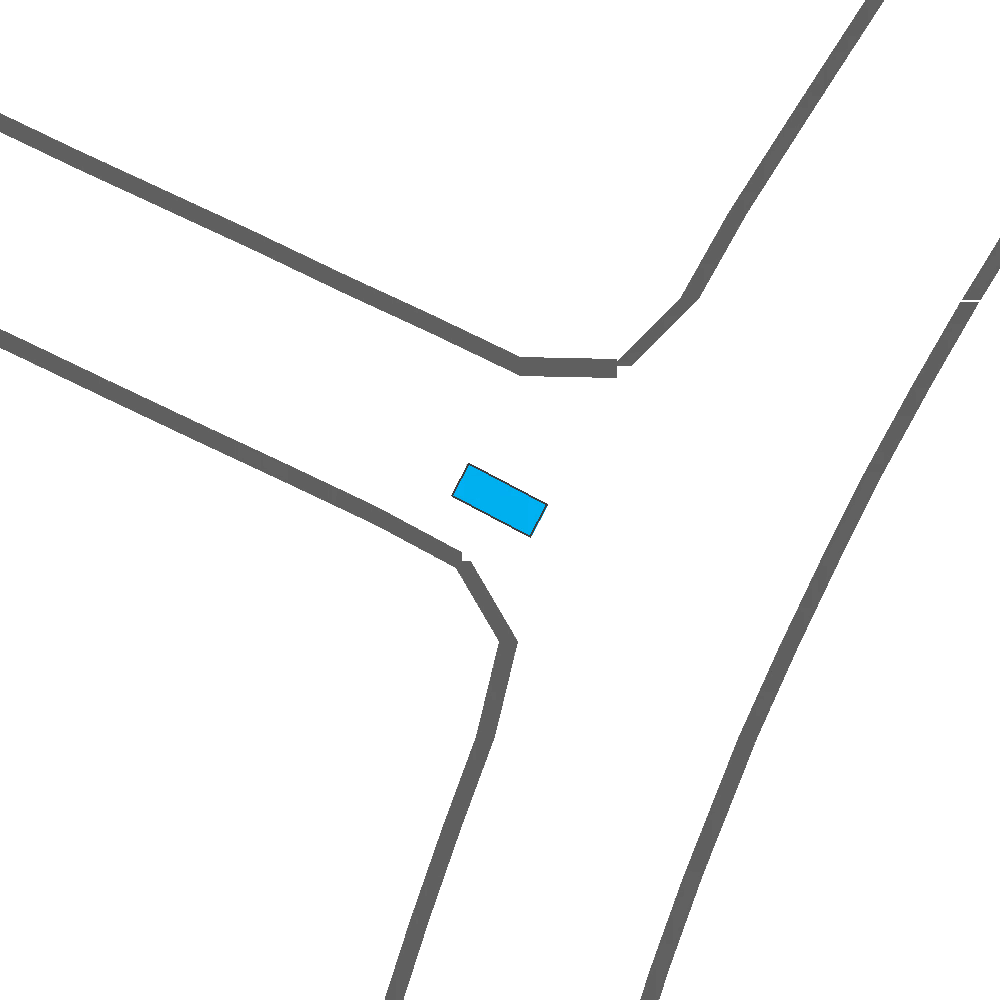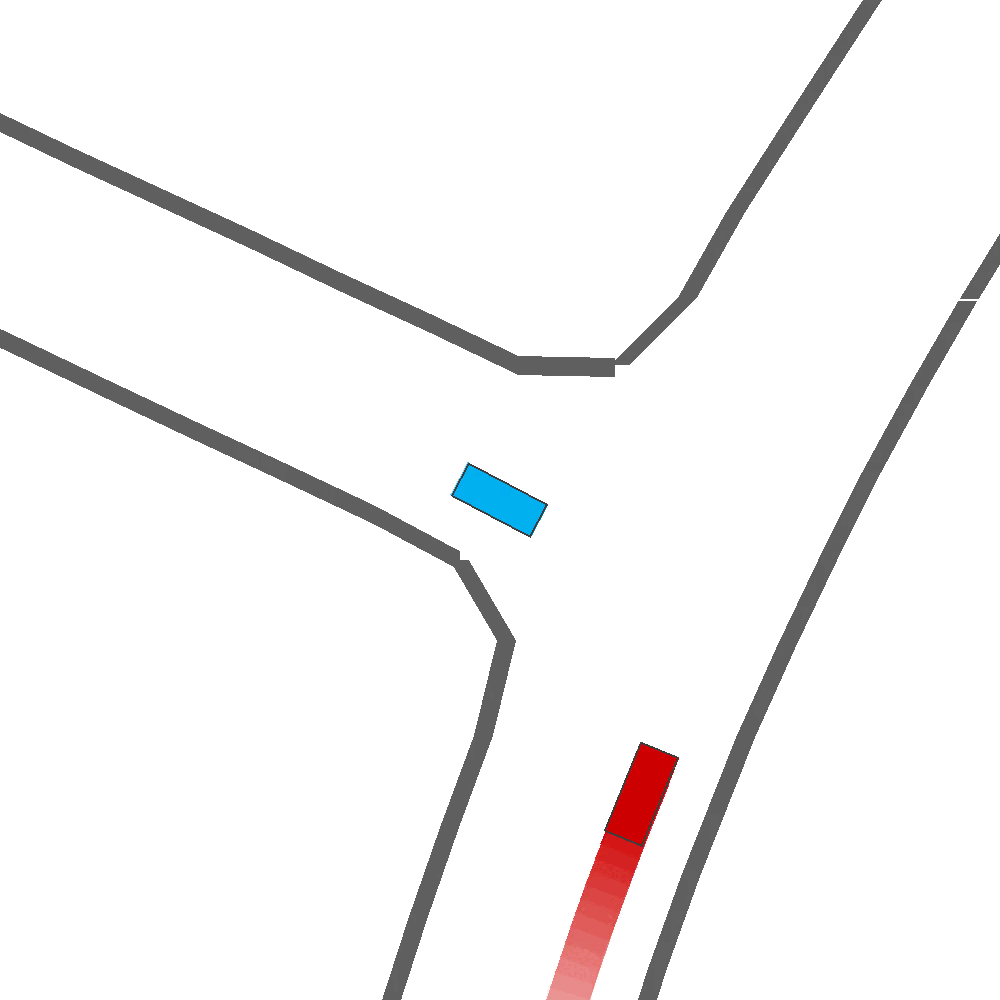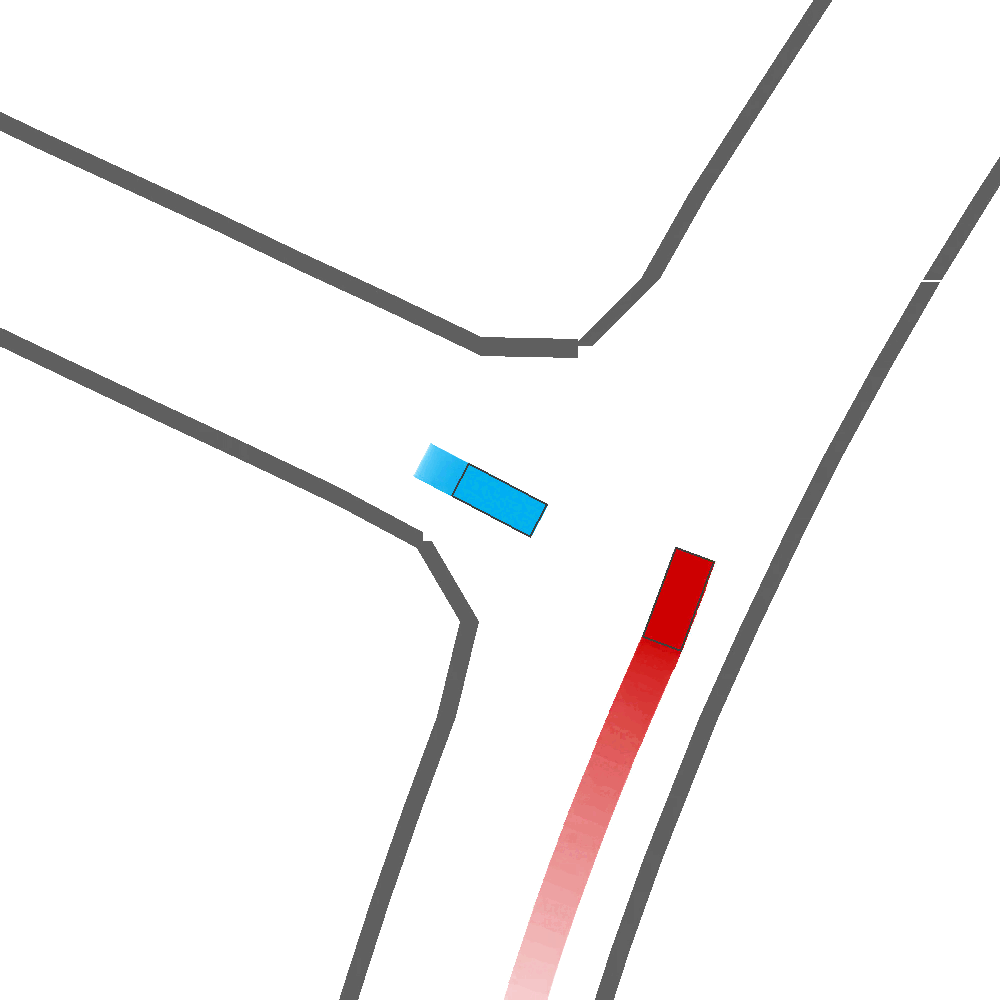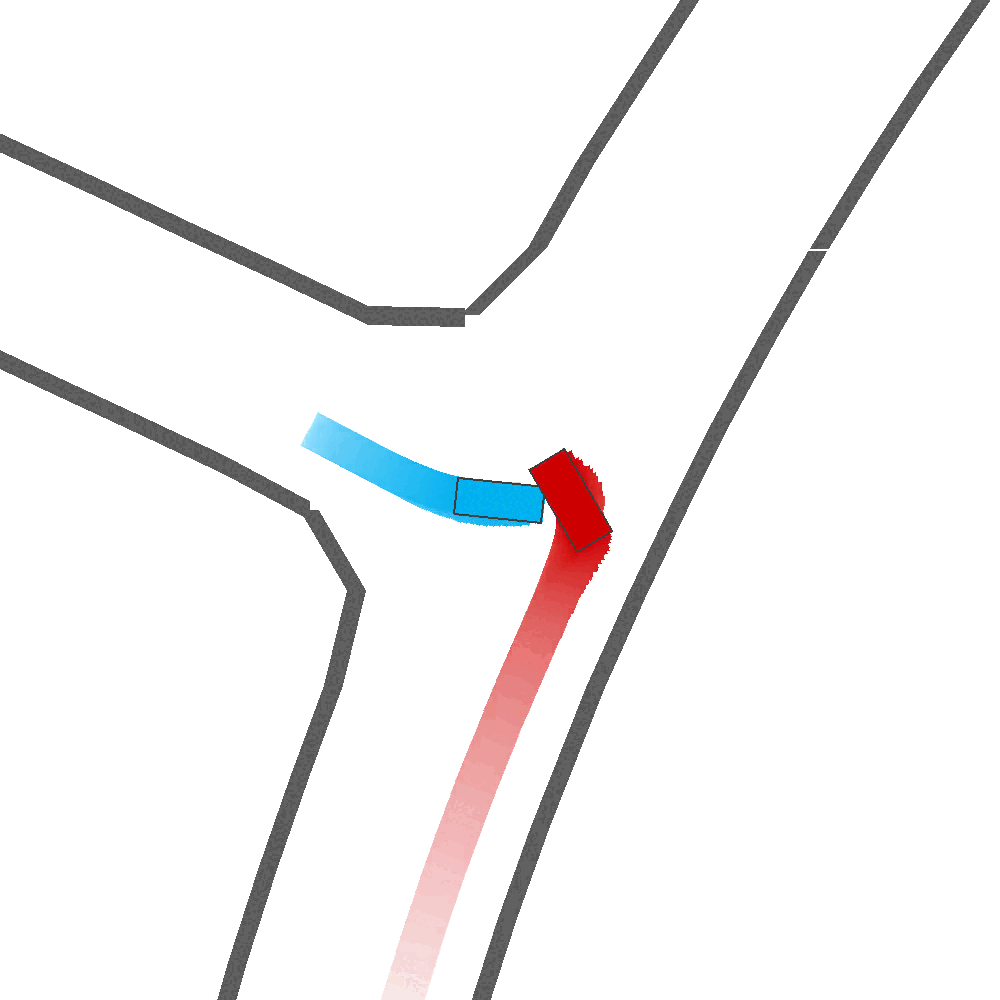
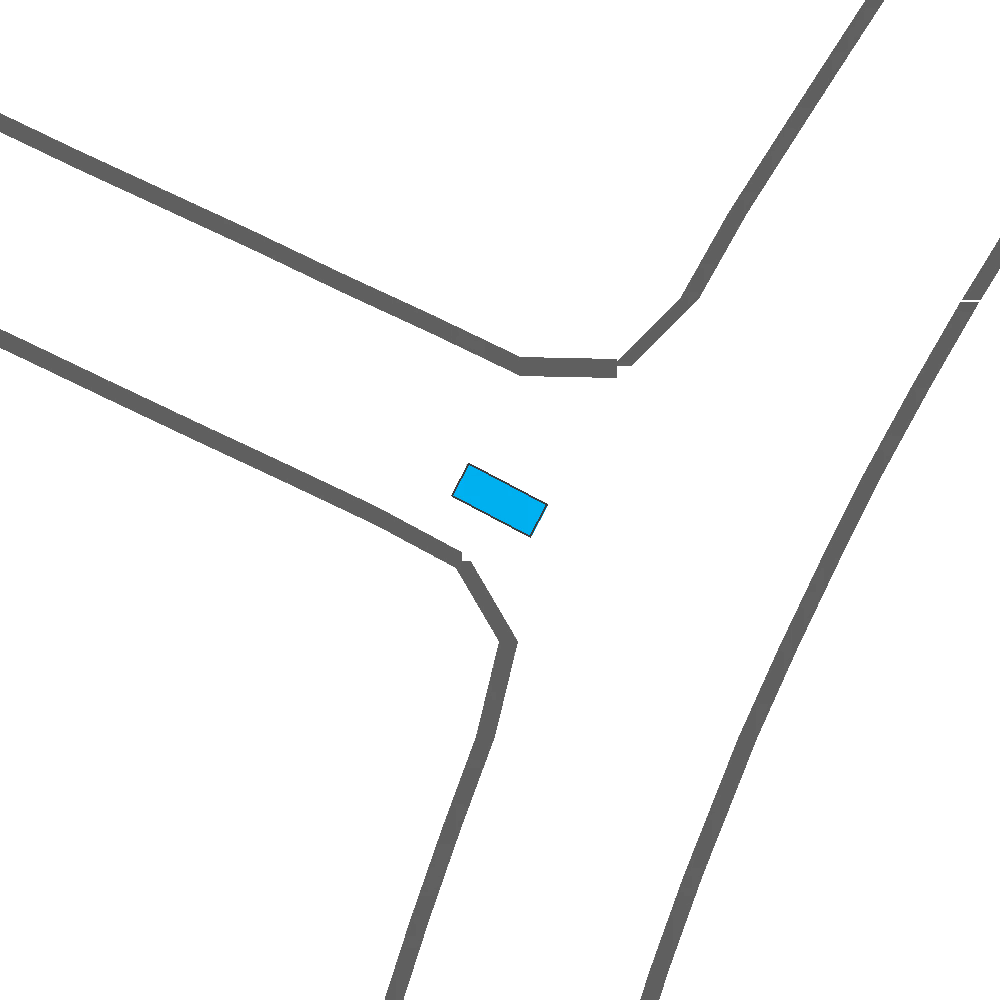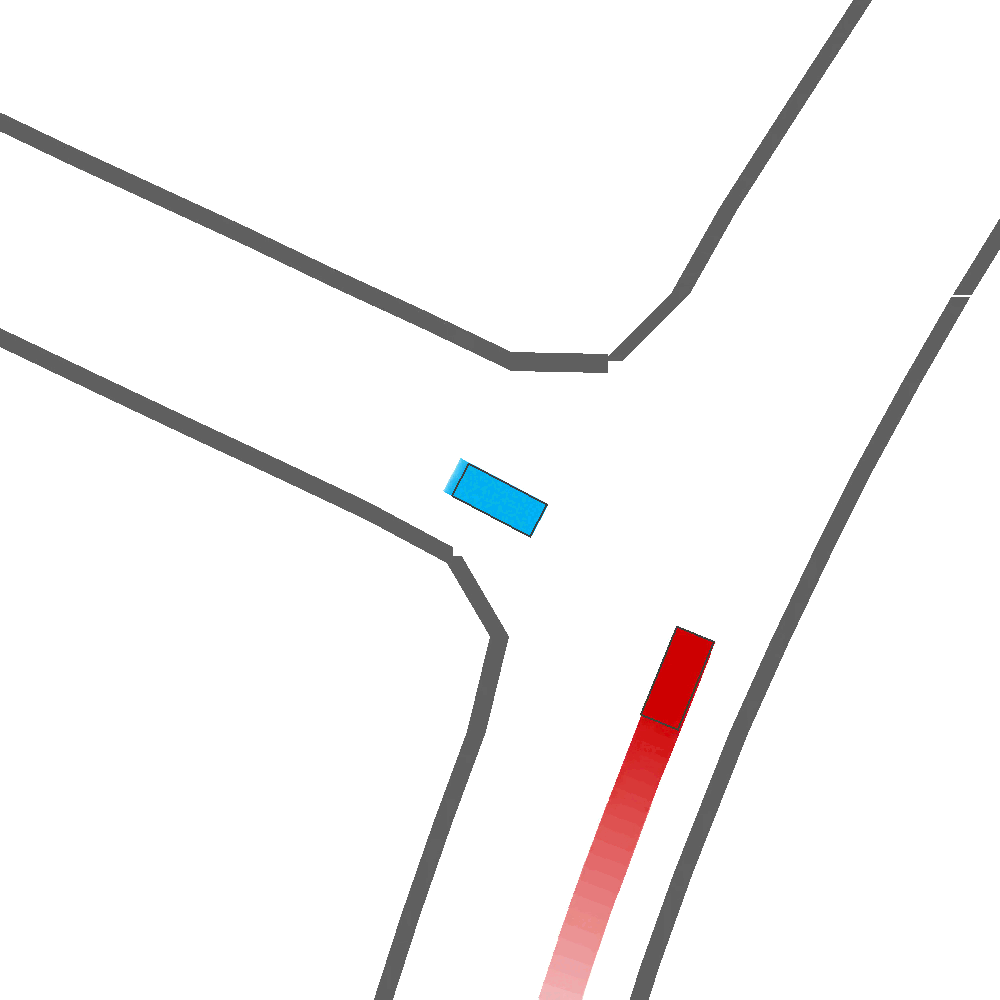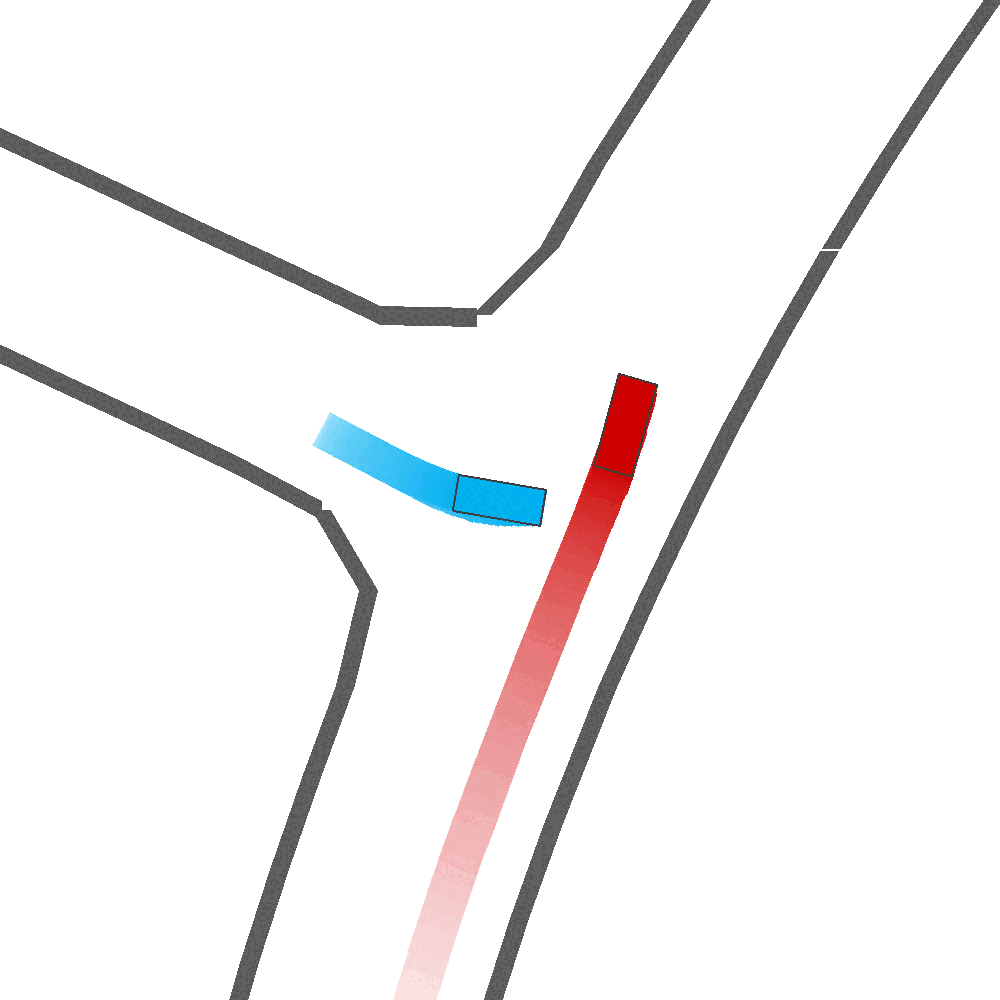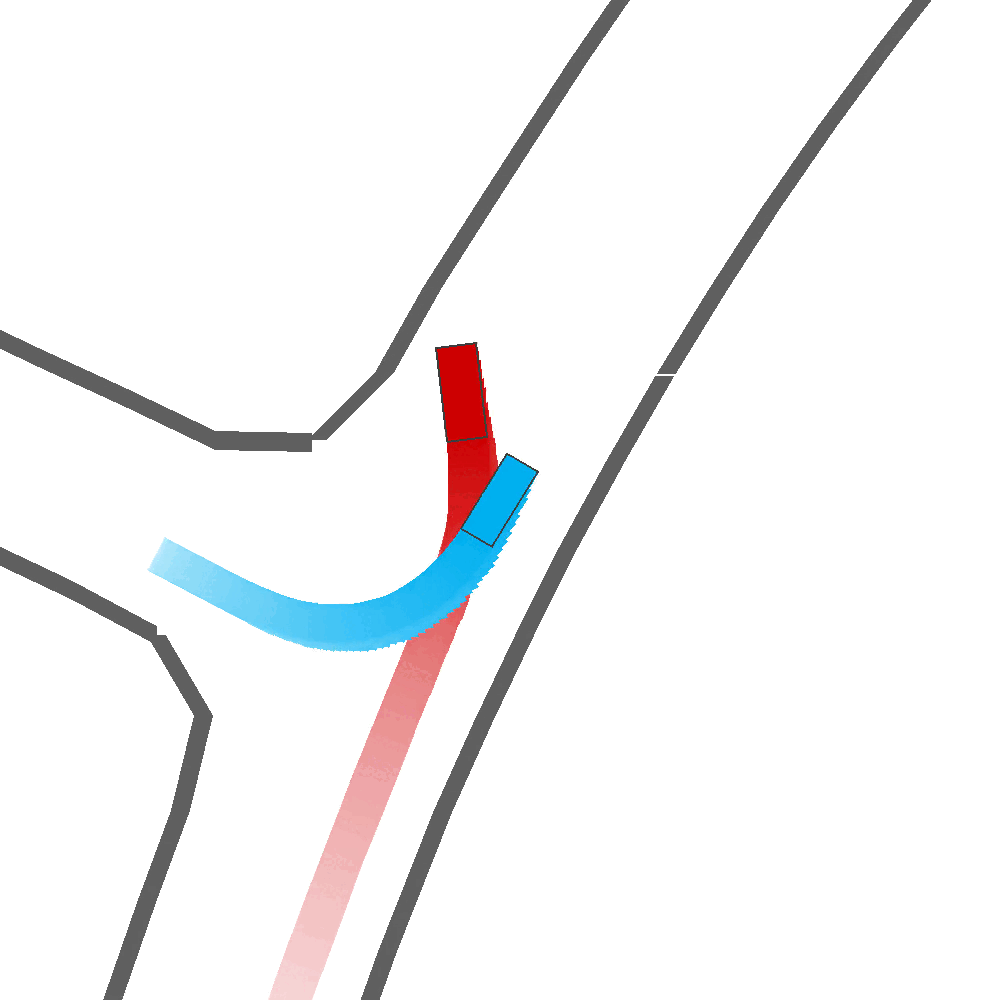
Qualitatively, we show more examples of CAT and GOOSE-generated scenes exhibiting overly-aggressive behavior, while the SEAL scene creates a more nuanced near-miss scenario, reactively avoiding a direct collision.
Check out our paper for more details and results!
BibTeX
@article{stoler2024seal,
title={SEAL: Towards Safe Autonomous Driving via Skill-Enabled Adversary Learning for Closed-Loop Scenario Generation},
author={Stoler, Benjamin and Navarro, Ingrid and Francis, Jonathan and Oh, Jean},
journal={arXiv preprint arXiv:2409.10320},
year={2024}
}